Zeitreihenanalyse: Definition, Arten, Techniken, Beispiele
Appinio Research · 26.01.2026 · 31min Lesezeit

Inhalt
Hast du dich jemals gefragt, wie Unternehmen zukünftige Trends vorhersagen oder wie Meteorologen das Wetter vorhersagen? Die Antwort liegt in der Zeitreihenanalyse! Sie ist wie der Blick in eine Kristallkugel für Daten und hilft uns zu verstehen, wie sich Dinge im Laufe der Zeit verändern. Von der Beobachtung von Aktienkursen bis hin zur Überwachung der Herzfrequenz - die Zeitreihenanalyse ist allgegenwärtig und entschlüsselt im Stillen die in den Daten verborgenen Muster und Trends. Ganz gleich, ob Unternehmer, der für die Zukunft plant, oder ein Forscher, der Klimamuster untersucht - die Beherrschung der Zeitreihenanalyse öffnet dir die Türen zu einer Welt voller Erkenntnisse und Möglichkeiten.
Was ist eine Zeitreihe?
Zeitreihendaten stellen Beobachtungen dar, die im Laufe der Zeit nacheinander gesammelt wurden. Sie sind durch die zeitliche Anordnung der Datenpunkte gekennzeichnet, wobei jede Beobachtung mit einem bestimmten Zeitstempel oder Zeitintervall verbunden ist. Bei der Zeitreihenanalyse werden die in solchen Daten vorhandenen Muster, Trends und Abhängigkeiten untersucht, um Vorhersagen zu treffen oder Erkenntnisse abzuleiten.
Verstehen von Zeitreihendaten
Zeitreihendaten können verschiedene Formen annehmen, z. B. Wirtschaftsindikatoren, Aktienkurse, Wettermessungen, Sensormesswerte und vieles mehr. Zu den wichtigsten Merkmalen von Zeitreihendaten gehören:
- Zeitliche Ordnung: Die Datenpunkte werden in regelmäßigen Abständen oder zu bestimmten Zeitpunkten erfasst, wobei jede Beobachtung nach der vorhergehenden erfolgt.
- Sequentielle Abhängigkeit: Die Beobachtungen in einer Zeitreihe sind häufig von früheren Beobachtungen abhängig, wobei sich Muster und Trends im Laufe der Zeit entwickeln.
- Saisonalität und Trends: Zeitreihendaten können saisonale Schwankungen, langfristige Trends oder andere systematische Muster aufweisen, die sich im Laufe der Zeit wiederholen.
- Unregelmäßige Schwankungen: Neben vorhersehbaren Mustern können Zeitreihendaten auch unregelmäßige Schwankungen oder Rauschen enthalten, die durch zufällige Schwankungen oder unvorhergesehene Ereignisse verursacht werden.
Anwendungen der Zeitreihenanalyse
Die Zeitreihenanalyse findet in verschiedenen Bereichen Anwendung, darunter:
- Finanzen: Vorhersage von Aktienkursen, Analyse von Wirtschaftstrends und Risikomanagement.
- Wirtschaftswissenschaften: Untersuchung von Konjunkturzyklen, Vorhersage des BIP-Wachstums und Analyse des Verbraucherverhaltens.
- Meteorologie: Vorhersage von Wettermustern, Klimamodellierung und Analyse von Umweltdaten.
- Ingenieurwesen: Überwachung der Anlagenleistung, vorausschauende Wartung und Prozesssteuerung.
- Gesundheitswesen: Analyse von Patientendaten, Vorhersage von Krankheitsausbrüchen und Überwachung von Vitaldaten.
Die Zeitreihenanalyse spielt eine entscheidende Rolle bei der Entscheidungsfindung, Ressourcenzuweisung, Risikobewertung und strategischen Planung in verschiedenen Branchen und Bereichen.
Die Bedeutung der Zeitreihenanalyse
- Identifizierung von Trends: Die Zeitreihenanalyse hilft bei der Erkennung zugrundeliegender Trends und Muster in den Daten und ermöglicht es Unternehmen, auf der Grundlage historischer Leistungen fundierte Entscheidungen zu treffen.
- Prognosen und Vorhersagen: Durch die Analyse vergangener Daten ermöglicht die Zeitreihenanalyse Unternehmen die Vorhersage künftiger Trends, die Antizipation von Marktveränderungen und eine entsprechende Planung.
- Risikomanagement: Das Verständnis der Variabilität und Vorhersagbarkeit von Zeitreihendaten ist für die Bewältigung von Risiken wie Börsenschwankungen, Konjunkturabschwüngen oder Unterbrechungen der Lieferkette unerlässlich.
- Ressourcen-Optimierung: Die Zeitreihenanalyse hilft bei der Optimierung der Ressourcenzuweisung, indem sie Nachfragespitzen, Produktionsengpässe oder Kapazitätsbeschränkungen aufzeigt.
- Leistungsüberwachung: Durch die Überwachung der wichtigsten Leistungsindikatoren (Key Performance Indicators, KPIs) im Zeitverlauf können Unternehmen Fortschritte verfolgen, verbesserungsbedürftige Bereiche identifizieren und bei Bedarf Korrekturmaßnahmen ergreifen.
- Erkennung von Anomalien: Die Erkennung von Anomalien oder Ausreißern in Zeitreihendaten kann Unternehmen auf ungewöhnliche Ereignisse aufmerksam machen, z. B. auf betrügerische Transaktionen, Geräteausfälle oder Netzwerkeinbrüche.
- Formulierung von Richtlinien: Regierungen und politische Entscheidungsträger nutzen Zeitreihenanalysen, um Wirtschaftsindikatoren zu analysieren, politische Maßnahmen zu formulieren und die Wirksamkeit von Interventionen im Zeitverlauf zu überwachen.
Die Zeitreihenanalyse bietet wertvolle Einblicke in die Dynamik sequenzieller Daten und ermöglicht es Unternehmen, verwertbare Informationen zu gewinnen, Risiken zu mindern und Chancen in einem dynamischen und sich entwickelnden Umfeld zu nutzen.
Konzepte der Zeitreihenanalyse
Bei der Zeitreihenanalyse geht es darum, die inhärenten Merkmale von zeitabhängigen Daten zu verstehen. Im Folgenden werden einige grundlegende Konzepte untersucht, die das Rückgrat der Zeitreihenanalyse bilden.
Komponenten der Zeitreihe
Das Verständnis der Komponenten einer Zeitreihe ist entscheidend, um ihr Verhalten zu analysieren und genaue Vorhersagen zu treffen. Zeitreihendaten bestehen in der Regel aus mehreren Komponenten:
- Trend: Die Trendkomponente stellt die langfristige Bewegung oder Richtung der Daten dar. Sie spiegelt wider, ob die Daten im Laufe der Zeit zunehmen, abnehmen oder relativ stabil bleiben. Die Identifizierung des Trends hilft Analysten, die zugrunde liegenden Wachstums- oder Abnahmemuster zu verstehen.
- Saisonalität: Die Saisonalität bezieht sich auf periodische Schwankungen oder Muster, die mit einer festen Häufigkeit auftreten und oft mit kalendarischen oder saisonalen Faktoren zusammenhängen. So können beispielsweise die Einzelhandelsumsätze in der Ferienzeit ein höheres Volumen aufweisen, während die Temperaturdaten das ganze Jahr über saisonale Schwankungen aufweisen können.
- Zyklische Muster: Bei zyklischen Mustern handelt es sich um wiederkehrende Schwankungen, die nicht streng periodisch sind. Diese Muster erstrecken sich in der Regel über mehrere Jahre und werden durch Wirtschafts-, Geschäfts- oder Umweltzyklen beeinflusst. Die Erkennung zyklischer Muster hilft Analysten, langfristige Wirtschaftstrends oder Geschäftszyklen zu verstehen.
- Unregelmäßige Schwankungen: Unregelmäßige Schwankungen, die auch als Rauschen oder Restkomponenten bezeichnet werden, stellen zufällige Schwankungen in den Daten dar, die nicht dem Trend, der Saisonalität oder zyklischen Mustern zugeschrieben werden können. Diese Schwankungen können auf unvorhersehbare Ereignisse, Messfehler oder externe Faktoren zurückzuführen sein.
Stationarität und Nicht-Stationarität
Stationarität ist ein grundlegendes Konzept in der Zeitreihenanalyse, da viele Prognosemodelle davon ausgehen, dass die zugrunde liegenden Daten stationär sind. Eine stationäre Zeitreihe weist im Zeitverlauf konstante statistische Eigenschaften auf, einschließlich eines konstanten Mittelwerts, einer konstanten Varianz und einer konstanten Autokovarianzstruktur. Im Gegensatz dazu weisen nicht-stationäre Zeitreihen sich ändernde statistische Eigenschaften auf, wie z. B. einen im Laufe der Zeit variierenden Mittelwert oder eine variierende Varianz.
Methoden zur Prüfung der Stationarität
Um die Stationarität zu beurteilen, können verschiedene statistische Tests eingesetzt werden:
- Augmented Dickey-Fuller (ADF) Test: Der ADF-Test prüft das Vorhandensein einer Einheitswurzel in den Zeitreihendaten. Eine Einheitswurzel weist auf Nicht-Stationarität hin, während ihr Fehlen auf Stationarität schließen lässt.
- Kwiatkowski-Phillips-Schmidt-Shin (KPSS)-Test: Mit dem KPSS-Test wird die Nullhypothese der Stationarität gegen die Alternative einer Einheitswurzel geprüft. Im Gegensatz zum ADF-Test testet der KPSS-Test ausdrücklich auf Stationarität und nicht auf Nicht-Stationarität.
Autokorrelation und partielle Autokorrelation
Die Autokorrelation misst den Grad der Korrelation zwischen einer Zeitreihe und ihren verzögerten Werten. Mit anderen Worten, sie quantifiziert die Beziehung zwischen Beobachtungen zu verschiedenen Zeitpunkten. Andererseits misst die partielle Autokorrelation die eindeutige Korrelation zwischen zwei Variablen unter Berücksichtigung des Einflusses anderer Variablen.
Interpretation der partiellen Autokorrelation
Partielle Autokorrelationsdiagramme bieten wertvolle Einblicke in die zugrunde liegenden Abhängigkeiten innerhalb einer Zeitreihe. Spitzen in der partiellen Autokorrelationsdarstellung weisen auf signifikante Verzögerungen hin, die die Auswahl geeigneter autoregressiver (AR) Terme in Prognosemodellen wie ARIMA leiten.
Zeitreihenzerlegung
Bei der Zeitreihendekomposition wird eine Zeitreihe in ihre einzelnen Komponenten zerlegt: Trend, Saisonalität, zyklische Muster und unregelmäßige Schwankungen. Mit Hilfe von Zerlegungstechniken können diese Komponenten isoliert werden, was die Analyse und Modellierung der einzelnen Aspekte der Daten erleichtert.
Methoden und Techniken
Für die Zerlegung von Zeitreihen können verschiedene Methoden verwendet werden:
- Additive Zerlegung: Bei der additiven Zerlegung wird die beobachtete Zeitreihe als die Summe ihrer einzelnen Komponenten betrachtet. Dieser Ansatz ist geeignet, wenn das Ausmaß der saisonalen Schwankungen im Laufe der Zeit konstant bleibt.
- Multiplikative Zerlegung: Bei der multiplikativen Zerlegung werden die einzelnen Komponenten multipliziert, um die ursprüngliche Zeitreihe zu rekonstruieren. Diese Methode wird bevorzugt, wenn die saisonalen Schwankungen proportionale Veränderungen im Verhältnis zum Trend aufweisen.
Die Zerlegung erleichtert ein tieferes Verständnis der zugrunde liegenden Muster, die den Zeitreihendaten zugrunde liegen, und ermöglicht so genauere Prognosen und Analysen.
Vorverarbeitung von Zeitreihendaten
Bevor mit einer Analyse oder Modellierung begonnen werden kann, müssen die Zeitreihendaten aufbereitet werden, um ihre Qualität und Zuverlässigkeit zu gewährleisten. Dies umfasst mehrere Schritte, um die Daten zu bereinigen, fehlende Werte zu verarbeiten, Ausreißer zu erkennen und die Daten angemessen zu transformieren.
Datenerfassung und -bereinigung
Der erste Schritt bei der Vorverarbeitung von Zeitreihendaten ist das Sammeln relevanter Daten aus verschiedenen Quellen, wie Datenbanken, APIs oder historischen Aufzeichnungen. Nach der Erfassung müssen die Daten häufig bereinigt werden, um Inkonsistenzen, Fehler oder irrelevante Informationen zu entfernen.
Die Datenbereinigung umfasst mehrere Aufgaben:
- Entfernen von Duplikaten: Identifizierung und Beseitigung doppelter Einträge, um die Datenintegrität zu gewährleisten.
- Behandlung von Inkonsistenzen: Beseitigung von Inkonsistenzen in der Datenformatierung, den Einheiten oder Skalen, um die Konsistenz des gesamten Datensatzes zu gewährleisten.
- Behandlung von Datenqualitätsproblemen: Identifizieren und Korrigieren von Fehlern oder Anomalien in den Daten, wie z. B. Rechtschreibfehler oder falsche Werte.
- Normalisierung der Daten: Skalierung numerischer Merkmale auf einen Standardbereich, um Vergleiche und Analysen zu erleichtern.
Für optimierte und effiziente Datenerfassungs- und -bereinigungsprozesse solltest du eine Plattform wie Appinio nutzen. Mit seiner intuitiven Benutzeroberfläche und seinen robusten Funktionen vereinfacht Appinio den Datenerfassungsprozess und ermöglicht es, nahtlos Erkenntnisse aus verschiedenen Quellen zu gewinnen. Durch die Automatisierung mühsamer Aufgaben und die Bereitstellung leistungsstarker Datenbereinigungstools ermöglicht Appinio, sich auf die Gewinnung aussagekräftiger Erkenntnisse aus deinen Zeitreihendaten zu konzentrieren.
Erlebe noch heute die Einfachheit und Effizienz der Datenerfassung mit Appinio. Bist du bereit, es in Aktion zu sehen? Buche jetzt eine Demo!
Handhabung fehlender Daten
Fehlende Daten sind ein häufiges Problem in Zeitreihendatensätzen und können aus verschiedenen Gründen auftreten, z. B. durch Fehlfunktionen von Geräten, menschliches Versagen oder Stichprobenprobleme. Der Umgang mit fehlenden Daten erfordert sorgfältige Überlegungen, um eine Verzerrung der Analyse- oder Modellierungsergebnisse zu vermeiden.
Für den Umgang mit fehlenden Daten können verschiedene Techniken eingesetzt werden:
- Imputation: Imputation fehlender Werte, indem diese durch geschätzte oder interpolierte Werte auf der Grundlage benachbarter Beobachtungen ersetzt werden. Gängige Imputationsmethoden sind die Mittelwert-Imputation, die Median-Imputation oder die regressionsbasierte Imputation.
- Vorwärts- oder Rückwärtsauffüllung: Auffüllen fehlender Werte mit dem jüngsten oder nachfolgenden Beobachtungswert.
- Interpolation: Schätzung fehlender Werte auf der Grundlage des in den umgebenden Datenpunkten beobachteten Trends oder Musters. Lineare Interpolation, Spline-Interpolation oder polynomiale Interpolation sind häufig verwendete Methoden.
Erkennung und Behandlung von Ausreißern
Ausreißer sind Datenpunkte, die erheblich vom Rest der Daten abweichen und statistische Analysen oder Modellierungsergebnisse verfälschen können. Die Erkennung und Behandlung von Ausreißern ist von entscheidender Bedeutung, um die Robustheit und Genauigkeit der Zeitreihenanalyse zu gewährleisten.
Für die Erkennung und Behandlung von Ausreißern können verschiedene Techniken eingesetzt werden:
- Visuelle Inspektion: Aufzeichnung der Zeitreihendaten, um Ausreißer, Spitzen oder ungewöhnliche Muster visuell zu erkennen.
- Statistische Tests: Verwendung statistischer Methoden wie Z-Tests, Grubbs-Test oder Dixon's Q-Test zur Erkennung von Ausreißern auf der Grundlage ihrer Abweichung vom Mittelwert oder anderer statistischer Eigenschaften.
- Trimmen oder Winsorisierung: Abschneiden oder Kappen von Extremwerten, um ihre Auswirkungen auf die Analyse abzuschwächen. Dabei werden die Ausreißer durch weniger extreme Werte innerhalb eines bestimmten Bereichs ersetzt.
Techniken der Datentransformation
Datentransformationstechniken werden eingesetzt, um die Varianz zu stabilisieren, Trends zu entfernen oder Stationarität in den Zeitreihendaten zu erreichen. Diese Transformationen sind oft notwendig, um die Annahmen bestimmter statistischer Modelle oder Prognosealgorithmen zu erfüllen.
Zu den Standard-Datentransformationstechniken gehören:
- Logarithmische Transformation: Die logarithmische Transformation ist nützlich, um die Varianz von Daten zu stabilisieren, die ein exponentielles Wachstum oder multiplikative Trends aufweisen.
- Differenzieren: Bei der Differenzierung werden aufeinanderfolgende Beobachtungen subtrahiert, um Trends zu entfernen oder Stationarität zu erreichen. Eine Differenzierung erster Ordnung wird üblicherweise verwendet, um lineare Trends zu entfernen, während eine Differenzierung höherer Ordnung für nichtlineare Trends erforderlich sein kann.
- Box-Cox-Transformation: Die Box-Cox-Transformation passt die Schiefe der Daten an, um sie symmetrischer zu machen, wodurch die Varianz stabilisiert und die Annahmen bestimmter statistischer Modelle erfüllt werden.
Durch den Einsatz dieser Vorverarbeitungstechniken können Analysten sicherstellen, dass ihre Zeitreihendaten sauber und konsistent sind und sich für die weitere Analyse und Modellierung eignen.
Methoden der Zeitreihenprognose
Die Vorhersage ist ein wichtiger Aspekt der Zeitreihenanalyse, der es Analysten ermöglicht, zukünftige Werte auf der Grundlage historischer Datenmuster vorherzusagen. Für die Vorhersage von Zeitreihendaten gibt es verschiedene Methoden und Modelle, die jeweils ihre Stärken und ihre Eignung für unterschiedliche Datentypen und Vorhersageszenarien haben.
Gleitende Durchschnitte
Gleitende Durchschnitte sind einfache, aber leistungsfähige Prognosetechniken, die den Durchschnitt eines festen Fensters vergangener Beobachtungen berechnen, um zukünftige Werte vorherzusagen. Sie tragen dazu bei, kurzfristige Schwankungen zu glätten und zugrunde liegende Trends in den Daten hervorzuheben.
Einfacher gleitender Durchschnitt (SMA)
Der einfache gleitende Durchschnitt (Simple Moving Average, SMA) berechnet den Durchschnitt einer bestimmten Anzahl von früheren Beobachtungen. Er wird berechnet, indem die Zeitreihenwerte innerhalb eines vordefinierten Fensters summiert und durch die Fenstergröße geteilt werden.
Formel für den einfachen gleitenden Durchschnitt (SMA):
SMA_t = (x_t-1 + x_t-2 + ... + x_t-n) / n
Wobei:
- SMA_t ist der einfache gleitende Durchschnitt zum Zeitpunkt t.
- n ist die Fenstergröße.
- x_t-n ist der Wert der Zeitreihe zum Zeitpunkt t-n.
Gewichteter gleitender Durchschnitt
Beim gewichteten gleitenden Mittelwert werden neuere Beobachtungen höher gewichtet als ältere Beobachtungen. Dadurch kann sich das Modell schneller an Veränderungen in den Daten anpassen, während gleichzeitig historische Informationen berücksichtigt werden.
Exponentielle Glättungsmethoden
Exponentielle Glättungsmethoden sind eine weitere Klasse von Prognosetechniken, die vergangenen Beobachtungen exponentiell abnehmende Gewichte zuweisen. Diese Methoden sind besonders effektiv, wenn es darum geht, kurzfristige Schwankungen zu erfassen und gleichzeitig den Gesamttrend in den Daten zu berücksichtigen.
Einfache exponentielle Glättung
Bei der einfachen exponentiellen Glättung werden den vergangenen Beobachtungen exponentiell abnehmende Gewichtungen zugewiesen, wobei die jüngsten Beobachtungen höher gewichtet werden. Die Prognose wird als gewichteter Durchschnitt der vorherigen Beobachtung und der vorherigen Prognose berechnet.
Formel für die einfache exponentielle Glättung:
F_t+1 = α * x_t + (1 - α) * F_t
Wobei:
- F_t+1 ist die Prognose für die nächste Zeitperiode.
- x_t ist der beobachtete Wert zum Zeitpunkt t.
- F_t ist die Prognose für den aktuellen Zeitraum.
- α ist der Glättungsparameter (0 < α < 1).
Doppelte exponentielle Glättung (Holt's Methode)
Die doppelte exponentielle Glättung, auch als Holt-Methode bekannt, erweitert die einfache exponentielle Glättung, um sowohl den Trend als auch die Saisonalität in den Daten zu erfassen. Dabei werden die Niveau- und Trendkomponenten getrennt geglättet.
Dreifache exponentielle Glättung (Holt-Winters-Methode)
Die dreifache exponentielle Glättung oder Holt-Winters-Methode erweitert die doppelte exponentielle Glättung, um die Saisonalität in die Prognose einzubeziehen. Sie enthält zusätzliche Glättungsparameter für die saisonale Komponente, so dass das Modell saisonale Muster in den Daten erfassen kann.
Autoregressives integriertes gleitendes Mittelwertmodell (ARIMA)
Das Modell des Autoregressiven Integrierten Gleitenden Durchschnitts (ARIMA) ist ein beliebtes Modell für Zeitreihenprognosen, das autoregressive (AR), differenzierende (I) und gleitende Durchschnittskomponenten (MA) kombiniert. ARIMA-Modelle können verschiedene Zeitreihenmuster erfassen, darunter Trends, Saisonalität und unregelmäßige Schwankungen.
Das ARIMA-Modell wird als ARIMA(p, d, q) bezeichnet, wobei:
- p die Ordnung der autoregressiven (AR) Komponente ist.
- d der Grad der Differenzierung ist, der erforderlich ist, um Stationarität zu erreichen.
- q die Ordnung der Komponente des gleitenden Durchschnitts (MA) ist.
ARIMA-Modelle werden häufig für die Vorhersage von Zeitreihendaten in verschiedenen Bereichen verwendet, darunter Finanzen, Wirtschaft und Meteorologie.
Saisonales ARIMA-Modell (SARIMA)
Das saisonale ARIMA-Modell (SARIMA) erweitert den ARIMA-Rahmen, um saisonale Komponenten in die Daten einzubeziehen. SARIMA-Modelle eignen sich gut für Zeitreihendaten, die saisonale Muster oder Schwankungen aufweisen.
Das SARIMA-Modell wird als SARIMA(p, d, q)(P, D, Q)m bezeichnet, wobei:
- p, d und q die nicht saisonalen AR-, Differenzierungs- bzw. MA-Komponenten darstellen.
- P, D und Q stellen die saisonalen AR-, Differenzierungs- und MA-Komponenten dar.
- m ist die saisonale Periode.
Durch die Berücksichtigung sowohl der nicht-saisonalen als auch der saisonalen Komponenten können SARIMA-Modelle genauere Prognosen für saisonale Zeitreihendaten liefern.
Andere Prognosemodelle
Neben den oben genannten Methoden gibt es mehrere andere Prognosemodelle und -techniken, die alle ihre Vorteile und Anwendungen haben:
- Saisonale Zerlegung von Zeitreihen (STL): STL zerlegt Zeitreihendaten in saisonale, Trend- und Residualkomponenten und ermöglicht so eine flexiblere Modellierung und Vorhersage.
- Vektorautoregression (VAR): VAR-Modelle werden zur Analyse und Prognose multivariater Zeitreihendaten verwendet, indem sie die Abhängigkeiten zwischen mehreren Variablen erfassen.
- Long Short-Term Memory (LSTM)-Netzwerke: LSTM-Netzwerke sind eine Art rekurrentes neuronales Netzwerk (RNN), das in der Lage ist, langfristige Abhängigkeiten in Zeitreihendaten zu erlernen, wodurch sie sich gut für sequenzielle Prognoseaufgaben eignen.
Jedes Prognosemodell hat Stärken und Schwächen, und die Wahl hängt von den spezifischen Merkmalen der Zeitreihendaten und den Prognosezielen ab. Experimente und Validierung sind unerlässlich, um das am besten geeignete Modell für eine bestimmte Vorhersageaufgabe zu bestimmen.
Bewertung und Auswahl von Zeitreihenmodellen
Die Sicherstellung der Genauigkeit und Zuverlässigkeit von Zeitreihenprognosemodellen ist für fundierte Entscheidungen und Vorhersagen von größter Bedeutung. Wir stellen Ihnen verschiedene Bewertungstechniken und Kriterien für die Auswahl des am besten geeigneten Prognosemodells vor.
Leistungsmetriken für Zeitreihenprognosen
Leistungsmetriken liefern quantitative Maße für die Genauigkeit und Effektivität eines Modells bei der Vorhersage zukünftiger Werte. Zur Bewertung der Leistung von Zeitreihenprognosemodellen werden in der Regel mehrere Metriken verwendet:
- Mittlerer absoluter Fehler (MAE): Der MAE misst die durchschnittliche absolute Differenz zwischen den vorhergesagten und den tatsächlichen Werten. Er bietet ein einfaches Maß für die Vorhersagegenauigkeit, wobei niedrigere Werte eine bessere Leistung anzeigen.
- Mittlerer quadratischer Fehler (MSE): Der MSE berechnet die durchschnittliche quadratische Differenz zwischen den vorhergesagten und den tatsächlichen Werten. Größere Fehler werden stärker bestraft als beim MAE, was ihn anfällig für Ausreißer macht.
- Root Mean Squared Error (RMSE): Der RMSE ist die Quadratwurzel aus dem MSE und liefert ein Maß für das durchschnittliche Ausmaß der Fehler in der Prognose. Wie MSE deuten auch niedrigere RMSE-Werte auf eine bessere Modellleistung hin.
- Mittlerer absoluter prozentualer Fehler (MAPE): MAPE berechnet die durchschnittliche prozentuale Differenz zwischen den vorhergesagten und den tatsächlichen Werten im Verhältnis zu den tatsächlichen Werten. Er liefert ein Maß für die relative Vorhersagegenauigkeit und ist daher hilfreich für den Vergleich von Modellen über verschiedene Datensätze oder Skalen hinweg.
Techniken der Kreuzvalidierung
Die Kreuzvalidierung ist ein entscheidender Schritt bei der Bewertung der Verallgemeinerbarkeit und Robustheit von Zeitreihenprognosemodellen. Dabei werden die Daten in Trainings- und Validierungssätze aufgeteilt und die Leistung des Modells iterativ für verschiedene Untersätze der Daten bewertet.
Train-Test-Aufteilung
Beim Train-Test-Split werden die Daten in einen Trainingssatz, der zum Trainieren des Modells verwendet wird, und einen separaten Testsatz, der zur Bewertung der Leistung des Modells dient, aufgeteilt. Das Modell wird auf historischen Daten trainiert und dann auf unbekannten Daten getestet, um seine Fähigkeit zur Generalisierung auf neue Beobachtungen zu bewerten.
K-Fold Cross-Validation
Bei der K-fachen Kreuzvalidierung werden die Daten in K gleich große Teilmengen oder Falten unterteilt. Das Modell wird K-mal trainiert, wobei jedes Mal K-1 Fold für das Training und der verbleibende Fold für die Validierung verwendet wird. Dieser Vorgang wird für jede Falte wiederholt, und die Leistungskennzahlen werden über alle Iterationen gemittelt, um eine Gesamtbewertung des Modells zu erhalten.
Kriterien für die Modellauswahl
Bei der Auswahl des am besten geeigneten Prognosemodells müssen verschiedene Faktoren berücksichtigt werden, darunter die Komplexität des Modells, seine Berechnungseffizienz und seine Fähigkeit, die zugrunde liegenden Muster in den Daten zu erfassen. Bei der Auswahl eines Prognosemodells können mehrere Kriterien eine Rolle spielen:
- Akaike Information Criterion (AIC): AIC ist ein Maß für die relative Qualität eines statistischen Modells, das die Anpassungsgüte mit der Komplexität des Modells in Einklang bringt. Niedrigere AIC-Werte weisen auf eine bessere Modellleistung hin, wobei einfachere Modelle gegenüber komplexeren Modellen bevorzugt werden.
- Bayessches Informationskriterium (BIC): Ähnlich wie AIC bestraft BIC die Modellkomplexität, um eine Überanpassung zu verhindern. Es bietet einen Kompromiss zwischen Modellanpassung und Parsimonie, wobei niedrigere BIC-Werte eine bessere Modellleistung anzeigen.
- Vorhersagegenauigkeit außerhalb der Stichprobe: Das wichtigste Kriterium für die Auswahl eines Modells ist letztlich seine Leistung bei der genauen Vorhersage zukünftiger Werte auf der Grundlage ungesehener Daten. Modelle sollten auf der Grundlage ihrer Fähigkeit bewertet werden, auf neue Beobachtungen zu verallgemeinern und genaue Vorhersagen in realen Szenarien zu treffen.
Durch die sorgfältige Auswertung von Leistungsmetriken, den Einsatz robuster Kreuzvalidierungstechniken und die Berücksichtigung von Modellauswahlkriterien können Analysten das am besten geeignete Prognosemodell für ihre spezifische Prognoseaufgabe ermitteln und genauere und zuverlässigere Vorhersagen treffen.
Beispiele für die Zeitreihenanalyse
Beispiele spielen eine entscheidende Rolle für das Verständnis der praktischen Anwendung von Zeitreihenanalyseverfahren. Lass uns also einige reale Szenarien betrachten, in denen die Zeitreihenanalyse angewendet werden kann.
Analyse des Aktienmarktes
Die Zeitreihenanalyse wird im Finanzwesen häufig eingesetzt, um Aktienkurse zu analysieren, Markttrends vorherzusagen und Investitionsentscheidungen zu treffen. Analysten nutzen historische Aktienkursdaten, um Muster zu identifizieren, Anomalien zu erkennen und Prognosemodelle für zukünftige Kurse zu entwickeln.
Beispiel: Analyse der historischen Performance einer Aktie mit Hilfe von Zeitreihenanalysetechniken wie gleitenden Durchschnitten, exponentieller Glättung und autoregressiven Modellen, um potenzielle Kauf- oder Verkaufsgelegenheiten zu ermitteln.
Nachfrageprognose
Unternehmen nutzen Zeitreihenanalysen, um die Nachfrage nach Produkten oder Dienstleistungen zu prognostizieren und so eine effiziente Bestandsverwaltung, Ressourcenzuweisung und Produktionsplanung zu ermöglichen. Durch die Analyse historischer Verkaufsdaten und externer Faktoren wie Saisonabhängigkeit und wirtschaftliche Trends können Unternehmen die künftige Nachfrage vorhersagen und ihre Strategien anpassen.
Beispiel: Mithilfe von Zeitreihenprognosemodellen lässt sich die künftige Nachfrage nach einem Produkt auf der Grundlage früherer Verkaufsdaten, Werbeaktivitäten und Markttrends vorhersagen, was Unternehmen dabei hilft, ihre Lagerbestände zu optimieren und Fehl- oder Überbestände zu vermeiden.
Wettervorhersage
Meteorologen stützen sich bei der Vorhersage von Wettermustern, bei der Vorhersage von Extremereignissen und bei der Ausgabe von Warnungen vor Unwettern auf die Zeitreihenanalyse. Meteorologische Agenturen können durch die Analyse historischer Wetterdaten, Satellitenbilder und atmosphärischer Modelle genaue und zeitnahe Vorhersagen für die Öffentlichkeit und Notfallhelfer erstellen.
Beispiel: Einsatz von Zeitreihenanalysetechniken wie ARIMA-Modellen (autoregressive integrierte gleitende Mittelwerte) und saisonale Zerlegung zur Vorhersage von Temperatur-, Niederschlags- und Windmustern, zur Unterstützung der Katastrophenvorsorge und Risikominderung.
Gesundheitsüberwachung
Im Gesundheitswesen wird die Zeitreihenanalyse zur Überwachung des Gesundheitszustands von Patienten, zur Vorhersage von Krankheitsausbrüchen und zur Analyse von Trends bei medizinischen Daten eingesetzt. Fachleute des Gesundheitswesens analysieren mit Zeitstempeln versehene Patientenakten, Sensordaten und physiologische Messungen, um Anomalien zu erkennen, Trends zu identifizieren und die Ergebnisse der Patienten zu verbessern.
Beispiel: Verwendung der Zeitreihenanalyse zur Überwachung von Vitaldaten wie Herzfrequenz, Blutdruck und Blutzuckerspiegel im Zeitverlauf, um Muster zu erkennen, die auf potenzielle Gesundheitsprobleme hinweisen und ein rechtzeitiges Eingreifen und eine Behandlung ermöglichen.
Verkehrsprognose
Stadtplaner und Verkehrsbehörden nutzen Zeitreihenanalysen, um Verkehrsstaus vorherzusagen, den Verkehrsfluss zu optimieren und Infrastrukturentwicklungsprojekte zu planen. Durch die Analyse von historischen Verkehrsdaten, Wetterbedingungen und Ereignissen, die sich auf die Verkehrsmuster auswirken, können Städte das Verkehrsmanagement verbessern und Staus reduzieren.
Beispiel: Anwendung von Zeitreihenprognoseverfahren zur Vorhersage des künftigen Verkehrsaufkommens auf Autobahnen oder städtischen Straßen auf der Grundlage historischer Verkehrsflussdaten, Fahrzeugzählungen und Tageszeitmuster, was eine effiziente Routenplanung und Verkehrsmanagementstrategien erleichtert.
Diese Beispiele verdeutlichen die Vielseitigkeit und Anwendbarkeit der Zeitreihenanalyse in verschiedenen Bereichen und zeigen, wie wichtig sie für die Entscheidungsfindung, Planung und Vorhersagemodellierung ist. Durch den Einsatz von Zeitreihenanalysetechniken und -tools können Unternehmen wertvolle Erkenntnisse gewinnen, fundierte Entscheidungen treffen und positive Ergebnisse in ihren jeweiligen Bereichen erzielen.
Fortgeschrittene Themen der Zeitreihenanalyse
Die Erforschung fortgeschrittener Themen in der Zeitreihenanalyse ermöglicht es Analysten, ihr Verständnis zu vertiefen und komplexere Vorhersageaufgaben zu bewältigen. Hier finden sich einige fortgeschrittene Techniken und Methoden zur Analyse von Zeitreihendaten.
Techniken zur saisonalen Anpassung
Saisonbereinigungstechniken sind unerlässlich, um saisonale Schwankungen aus Zeitreihendaten zu entfernen, damit sich Analysten auf die zugrunde liegenden Trends und unregelmäßigen Schwankungen konzentrieren können. Für die saisonale Bereinigung gibt es mehrere Methoden:
- X-12-ARIMA: X-12-ARIMA ist ein weit verbreitetes Softwaretool, das vom U.S. Census Bureau für die saisonale Bereinigung von Zeitreihendaten entwickelt wurde. Es beinhaltet die ARIMA-Modellierung zur Schätzung und Entfernung saisonaler Komponenten aus den Daten.
- Seasonal Decomposition of Time Series (STL): Mit Hilfe eines robusten und flexiblen Ansatzes zerlegt STL Zeitreihendaten in saisonale, Trend- und Restkomponenten. Dadurch können Analysten jede Komponente separat analysieren und modellieren, was zu genaueren Prognosen führt.
Vorhersage mit exogenen Variablen
Die Einbeziehung exogener Variablen, die auch als externe oder Prädiktorvariablen bezeichnet werden, in Zeitreihenvorhersagemodelle kann die Vorhersagegenauigkeit verbessern, indem zusätzliche Informationen erfasst werden, die die Zielvariable beeinflussen. Zu den exogenen Variablen können Wirtschaftsindikatoren, Wetterdaten oder andere relevante Faktoren gehören.
- Vektorautoregression mit exogenen Variablen (VARX): VARX-Modelle erweitern die traditionellen VAR-Modelle durch die Einbeziehung exogener Variablen. Sie erfassen die Abhängigkeiten zwischen mehreren Zeitreihenvariablen und berücksichtigen dabei den Einfluss externer Faktoren.
- Dynamische Regressionsmodelle: Dynamische Regressionsmodelle beziehen sowohl verzögerte Werte der Zielvariablen als auch exogene Variablen ein, um zukünftige Werte vorherzusagen. Diese Modelle sind besonders nützlich, wenn die Beziehung zwischen der Zielvariablen und externen Faktoren komplex oder nichtlinear ist.
Multivariate Zeitreihenanalyse
Bei der multivariaten Zeitreihenanalyse werden mehrere Zeitreihenvariablen gleichzeitig analysiert und prognostiziert, wobei die Abhängigkeiten und Wechselwirkungen zwischen den Variablen berücksichtigt werden. Dieser Ansatz ermöglicht es den Analysten, komplexe Beziehungen und Abhängigkeiten in den Daten zu erfassen.
- Vektorielle Autoregression (VAR): VAR-Modelle sind eine beliebte Wahl für die multivariate Zeitreihenanalyse. Sie modellieren die gemeinsame Dynamik mehrerer Variablen unter Verwendung verzögerter Werte aller Variablen als Prädiktoren.
- Granger-Kausalitätsanalyse: Die Granger-Kausalitätsanalyse testet, ob eine Zeitreihenvariable die zukünftigen Werte einer anderen Variablen vorhersagen kann, und liefert so Einblicke in die kausalen Beziehungen zwischen Variablen.
Nichtlineare Zeitreihenmodelle
Nichtlineare Zeitreihenmodelle erfassen komplexe und nichtlineare Beziehungen in den Daten und ermöglichen eine flexiblere und genauere Vorhersage. Diese Modelle sind von Vorteil, wenn die zugrundeliegende Dynamik der Zeitreihe nichtlinear ist oder ein chaotisches Verhalten aufweist.
- Nichtlineare autoregressive exogene Modelle (NARX): NARX-Modelle erweitern die traditionellen linearen ARX-Modelle durch die Einführung nichtlinearer Transformationen der Eingangs- und Ausgangsvariablen. Sie können komplexe Abhängigkeiten und Muster erfassen, die linearen Modellen möglicherweise entgehen.
- Neuronale Netzwerkmodelle: Neuronale Netzwerkmodelle, wie z. B. neuronale Feedforward-Netzwerke oder rekurrente neuronale Netzwerke (RNNs), können komplexe nichtlineare Beziehungen in Zeitreihendaten lernen. Sie eignen sich hervorragend zur Erfassung von Mustern und Abhängigkeiten, die mit herkömmlichen linearen Ansätzen nur schwer zu modellieren sind.
Clustering und Klassifizierung von Zeitreihen
Clustering- und Klassifizierungsverfahren für Zeitreihen zielen darauf ab, ähnliche Zeitreihendaten zu gruppieren oder sie auf der Grundlage ihrer Muster und Merkmale in vordefinierte Kategorien einzuordnen. Diese Verfahren finden Anwendung bei der Erkennung von Anomalien, der Mustererkennung und der Segmentierung.
- K-Means-Clustering: Beim K-Means-Clustering werden Zeitreihendaten auf der Grundlage der Ähnlichkeit ihrer zeitlichen Muster in K-Cluster unterteilt. Es ist nützlich für die Identifizierung von Gruppen von Zeitreihen mit ähnlichem Verhalten.
- Dynamisches Time Warping (DTW): DTW ist eine abstandsbasierte Methode zur Messung der Ähnlichkeit zwischen Zeitreihendaten unter Berücksichtigung von Variationen in ihrer zeitlichen Ausrichtung. Sie wird häufig für das Clustering von Zeitreihen und für Klassifizierungsaufgaben verwendet.
Die Erforschung fortgeschrittener Themen in der Zeitreihenanalyse eröffnet neue Wege zum Verständnis komplexer Datenmuster, zur Verbesserung der Vorhersagegenauigkeit und zur Gewinnung wertvoller Erkenntnisse über zugrunde liegende Trends und Beziehungen. Durch die Einbeziehung dieser fortgeschrittenen Techniken in ihr analytisches Toolkit können Analysten eine breite Palette von Prognoseaufgaben bewältigen und fundiertere Entscheidungen auf der Grundlage von Zeitreihendaten treffen.
Schlussfolgerung für die Zeitreihenanalyse
Bei der Zeitreihenanalyse geht es nicht nur um die Berechnung von Zahlen, sondern auch um die Aufdeckung von Geschichten, die in den Daten verborgen sind. Wenn wir verstehen, wie sich Dinge im Laufe der Zeit verändern, erhalten wir wertvolle Einblicke in die Vergangenheit, die Gegenwart und die Zukunft. Egal, ob Sie ein erfahrener Analytiker sind oder gerade erst in die Welt der Daten eintauchen, denke daran, dass jeder Trend, jede Schwankung eine Geschichte zu erzählen hat. Forsche weiter, analysiere weiter, und lass dich von den Daten zu besseren Entscheidungen und einer besseren Zukunft führen.
Aber denke daran, dass die Zeitreihenanalyse zwar ein leistungsstarkes Instrumentarium für Prognosen und Vorhersagen bietet, aber keine Kristallkugel ist. Die Zukunft ist ungewiss, und auf dem Weg dorthin gibt es immer wieder Überraschungen. Nimm also die Ungewissheit in Kauf, lerne aus den Daten und verfeinere die Modelle weiter. Schließlich liegt die Schönheit der Zeitreihenanalyse nicht darin, die Zukunft mit Sicherheit vorherzusagen, sondern darin, die Muster und Trends zu verstehen, die unsere Welt prägen.
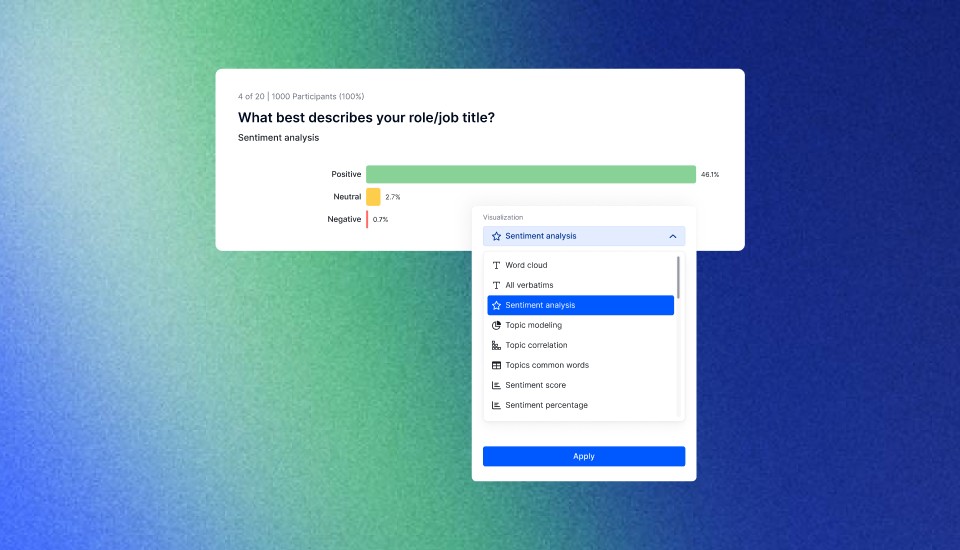
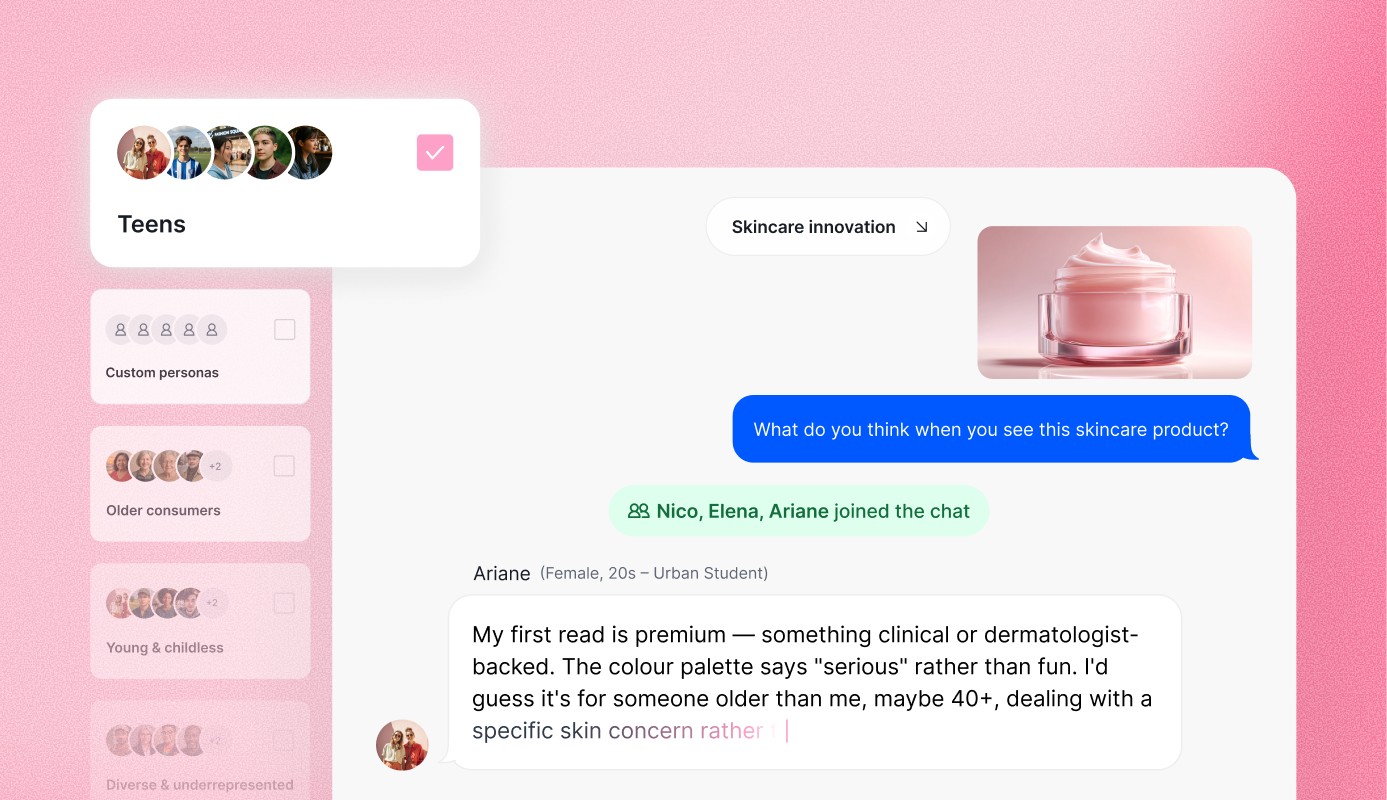
Wie führt man eine Zeitreihenanalyse in wenigen Minuten durch?
Wir stellen Appinio vor, die ideale Plattform für die einfache und schnelle Durchführung von Zeitreihenanalysen. Als Echtzeit-Marktforschungsplattform versetzt Appinio Unternehmen in die Lage, Echtzeit-Konsumenteneinblicke für intelligentere, datengestützte Entscheidungen nutzbar zu machen. Mit uns musst du dich nicht mit der Komplexität von Forschung und Technologie auseinandersetzen - wir übernehmen die schwere Arbeit, damit du dich auf das konzentrieren kannst, was wirklich wichtig ist: die Nutzung von Echtzeit-Konsumenteneinblicken zur Förderung des Geschäftserfolgs.
Was Appinio auszeichnet:
- Von Fragen zu Erkenntnissen in wenigen Minuten: Verabschiede dich von langwierigen Forschungsprozessen. Mit Appinio kannst du innerhalb weniger Minuten von der Formulierung von Fragen zu verwertbaren Erkenntnissen gelangen.
- Intuitive Plattform für jedermann: Du brauchst keinen Doktortitel in Forschung, um Appinio zu nutzen. Unsere Plattform ist so konzipiert, dass sie intuitiv und benutzerfreundlich ist, so dass jeder mühelos Marktforschung betreiben kann.
- Schnelle Reaktionszeit: Du brauchst schnell Antworten? Mit einer durchschnittlichen Feldzeit von weniger als 23 Minuten für 1.000 Befragte liefert Appinio zeitnahe Erkenntnisse, die deinen Entscheidungsprozess unterstützen.
Fakten, die im Kopf bleiben 🧠
Interessiert an weiteren Insights? Dann sind unsere Reports genau das richtige, mit Trends und Erkenntnissen zu allen möglichen Themen.