Time Series Analysis: Definition, Types, Techniques, Examples
Appinio Research · 30.10.2025 · 31min read

Content
Ever wondered how businesses predict future trends or how meteorologists forecast the weather? The answer lies in time series analysis! It's like looking into a crystal ball for data, helping us understand how things change over time. From tracking stock prices to monitoring heart rates, time series analysis is everywhere, quietly unraveling patterns and trends hidden within the data. Whether you're a business owner planning for the future or a researcher studying climate patterns, mastering time series analysis opens doors to a world of insights and possibilities.
What is a Time Series?
Time series data represents observations collected sequentially over time. It is characterized by the temporal ordering of data points, with each observation associated with a specific timestamp or time interval. Time series analysis involves studying the patterns, trends, and dependencies present in such data to make predictions or infer insights.
Understanding Time Series Data
Time series data can take various forms, including economic indicators, stock prices, weather measurements, sensor readings, and more. The key characteristics of time series data include:
- Temporal Order: Data points are collected at regular intervals or timestamps, with each observation occurring after the previous one.
- Sequential Dependency: Observations in a time series are often dependent on previous observations, with patterns and trends evolving over time.
- Seasonality and Trends: Time series data may exhibit seasonal fluctuations, long-term trends, or other systematic patterns that repeat over time.
- Irregular Variations: In addition to predictable patterns, time series data may contain irregular variations or noise caused by random fluctuations or unforeseen events.
Applications of Time Series Analysis
Time series analysis finds applications in various fields, including:
- Finance: Forecasting stock prices, analyzing economic trends, and risk management.
- Economics: Studying business cycles, forecasting GDP growth, and analyzing consumer behavior.
- Meteorology: Predicting weather patterns, climate modeling, and analyzing environmental data.
- Engineering: Monitoring equipment performance, predictive maintenance, and process control.
- Healthcare: Analyzing patient data, predicting disease outbreaks, and monitoring vital signs.
Time series analysis plays a crucial role in decision-making, resource allocation, risk assessment, and strategic planning across diverse industries and domains.
Importance of Time Series Analysis
- Trend Identification: Time series analysis helps identify underlying trends and patterns in data, enabling businesses to make informed decisions based on historical performance.
- Forecasting and Prediction: By analyzing past data, time series analysis allows organizations to forecast future trends, anticipate market changes, and plan accordingly.
- Risk Management: Understanding the variability and predictability of time series data is essential for managing risks, such as stock market fluctuations, economic downturns, or supply chain disruptions.
- Resource Optimization: Time series analysis helps optimize resource allocation by identifying peak demand periods, production bottlenecks, or capacity constraints.
- Performance Monitoring: Monitoring key performance indicators (KPIs) over time allows organizations to track progress, identify areas for improvement, and take corrective actions as needed.
- Anomaly Detection: Detecting anomalies or outliers in time series data can alert organizations to unusual events, such as fraudulent transactions, equipment failures, or network intrusions.
- Policy Formulation: Governments and policymakers use time series analysis to analyze economic indicators, formulate policies, and monitor the effectiveness of interventions over time.
Time series analysis provides valuable insights into the dynamics of sequential data, enabling organizations to extract actionable intelligence, mitigate risks, and capitalize on opportunities in a dynamic and evolving environment.
Time Series Analysis Concepts
Time series analysis involves understanding the inherent characteristics of time-dependent data. Let's explore some fundamental concepts that form the backbone of time series analysis.
Time Series Components
Understanding the components of a time series is crucial for dissecting its behavior and making accurate predictions. Time series data typically comprises several components:
- Trend: The trend component represents the long-term movement or direction of the data. It reflects whether the data is increasing, decreasing, or remaining relatively stable over time. Identifying the trend helps analysts understand the underlying growth or decline patterns.
- Seasonality: Seasonality refers to periodic fluctuations or patterns that occur with a fixed frequency, often related to calendar or seasonal factors. For example, retail sales may exhibit higher volumes during holiday seasons, while temperature data might show seasonal variations throughout the year.
- Cyclical Patterns: Cyclical patterns involve recurring fluctuations that are not strictly periodic. These patterns typically span multiple years and are influenced by economic, business, or environmental cycles. Identifying cyclical patterns helps analysts understand long-term economic trends or business cycles.
- Irregular Variations: Irregular variations, also known as noise or residual components, represent random fluctuations in the data that cannot be attributed to the trend, seasonality, or cyclical patterns. These variations may result from unpredictable events, measurement errors, or external factors.
Stationarity and Non-Stationarity
Stationarity is a fundamental concept in time series analysis, as many forecasting models assume that the underlying data is stationary. A stationary time series exhibits constant statistical properties over time, including a constant mean, variance, and autocovariance structure. On the contrary, non-stationary time series display changing statistical properties, such as a varying mean or variance over time.
Methods for Testing Stationarity
To assess stationarity, various statistical tests can be employed:
- Augmented Dickey-Fuller (ADF) Test: The ADF test evaluates the presence of a unit root in the time series data. A unit root indicates non-stationarity, while its absence suggests stationarity.
- Kwiatkowski-Phillips-Schmidt-Shin (KPSS) Test: The KPSS test assesses the null hypothesis of stationarity against the alternative of a unit root. Contrary to the ADF test, the KPSS test explicitly tests for stationarity rather than non-stationarity.
Autocorrelation and Partial Autocorrelation
Autocorrelation measures the degree of correlation between a time series and its lagged values. In other words, it quantifies the relationship between observations at different time points. On the other hand, partial autocorrelation measures the unique correlation between two variables while controlling for the influence of other variables.
Interpretation of Partial Autocorrelation
Partial autocorrelation plots provide valuable insights into the underlying dependencies within a time series. Peaks in the partial autocorrelation plot indicate significant lags, guiding the selection of appropriate autoregressive (AR) terms in forecasting models such as ARIMA.
Time Series Decomposition
Time series decomposition involves separating a time series into its constituent components: trend, seasonality, cyclical patterns, and irregular variations. Decomposition techniques help isolate these components, making it easier to analyze and model each aspect of the data.
Methods and Techniques
Several methods can be used for time series decomposition:
- Additive Decomposition: In additive decomposition, the observed time series is considered as the sum of its individual components. This approach is suitable when the magnitude of seasonal fluctuations remains constant over time.
- Multiplicative Decomposition: Multiplicative decomposition involves multiplying the individual components to reconstruct the original time series. This method is preferred when the seasonal fluctuations exhibit proportional changes relative to the trend.
Decomposition facilitates a deeper understanding of the underlying patterns driving the time series data, thereby enabling more accurate forecasting and analysis.
Time Series Data Preprocessing
Before embarking on any analysis or modeling, it's crucial to preprocess time series data to ensure its quality and reliability. This involves several steps to clean, handle missing values, detect outliers, and transform the data appropriately.
Data Collection and Cleaning
The first step in time series data preprocessing is collecting relevant data from various sources, such as databases, APIs, or historical records. Once obtained, the data often requires cleaning to remove inconsistencies, errors, or irrelevant information.
Data cleaning involves several tasks:
- Removing Duplicates: Identifying and eliminating duplicate entries to ensure data integrity.
- Handling Inconsistencies: Addressing inconsistencies in data formatting, units, or scales to maintain consistency across the dataset.
- Addressing Data Quality Issues: Identifying and correcting errors or anomalies in the data, such as misspellings or incorrect values.
- Data Normalization: Scaling numerical features to a standard range to facilitate comparison and analysis.
For streamlined and efficient data collection and cleaning processes, consider leveraging a platform like Appinio. With its intuitive interface and robust features, Appinio simplifies the data collection process, allowing you to gather insights from diverse sources seamlessly. By automating tedious tasks and providing powerful data-cleaning tools, Appinio enables you to focus on extracting meaningful insights from your time series data.
Experience the ease and efficiency of data collection with Appinio today. Ready to see it in action? Book a demo now!
Missing Data Handling
Missing data is a common issue in time series datasets and can arise for various reasons, including equipment malfunction, human error, or sampling issues. Dealing with missing data requires careful consideration to avoid biasing the analysis or modeling results.
Several techniques can be employed to handle missing data:
- Imputation: Imputing missing values by replacing them with estimated or interpolated values based on neighboring observations. Common imputation methods include mean imputation, median imputation, or regression-based imputation.
- Forward or Backward Fill: Filling missing values with the most recent or subsequent observed value.
- Interpolation: Estimating missing values based on the trend or pattern observed in the surrounding data points. Linear interpolation, spline interpolation, or polynomial interpolation are commonly used methods.
Outlier Detection and Treatment
Outliers are data points that deviate significantly from the rest of the data and can distort statistical analyses or modeling results. Detecting and addressing outliers is essential for ensuring the robustness and accuracy of time series analysis.
Several techniques can be employed for outlier detection and treatment:
- Visual Inspection: Plotting the time series data to visually identify outliers, spikes, or unusual patterns.
- Statistical Tests: Using statistical methods such as Z-tests, Grubbs' test, or Dixon's Q-test to detect outliers based on their deviation from the mean or other statistical properties.
- Trimming or Winsorization: Truncating or capping extreme values to mitigate their impact on the analysis. This involves replacing outliers with less extreme values within a specified range.
Data Transformation Techniques
Data transformation techniques are employed to stabilize variance, remove trends, or achieve stationarity in the time series data. These transformations are often necessary to meet the assumptions of specific statistical models or forecasting algorithms.
Standard data transformation techniques include:
- Logarithmic Transformation: Logarithmic transformation is useful for stabilizing variance in data exhibiting exponential growth or multiplicative trends.
- Differencing: Differencing involves subtracting consecutive observations to remove trends or achieve stationarity. First-order differencing is commonly used to remove linear trends, while higher-order differencing may be necessary for nonlinear trends.
- Box-Cox Transformation: The Box-Cox transformation adjusts the skewness of the data to make it more symmetric, thereby stabilizing variance and meeting the assumptions of certain statistical models.
By employing these preprocessing techniques, analysts can ensure that their time series data is clean, consistent, and suitable for further analysis and modeling.
Time Series Forecasting Methods
Forecasting is a critical aspect of time series analysis, enabling analysts to predict future values based on historical data patterns. Various methods and models exist for forecasting time series data, each with its strengths and suitability for different types of data and forecasting scenarios.
Moving Averages
Moving averages are simple yet powerful forecasting techniques that calculate the average of a fixed window of past observations to predict future values. They help smooth out short-term fluctuations and highlight underlying trends in the data.
Simple Moving Average (SMA)
The Simple Moving Average (SMA) calculates the average of a specified number of previous observations. It is calculated by summing up the time series values within a predefined window and dividing by the window size.
Formula for Simple Moving Average (SMA):
SMA_t = (x_t-1 + x_t-2 + ... + x_t-n) / n
Where:
- SMA_t is the Simple Moving Average at time t.
- n is the window size.
- x_t-n represents the value of the time series at time t-n.
Weighted Moving Average
In the Weighted Moving Average, more recent observations are assigned higher weights than older observations. This allows the model to adapt more quickly to changes in the data while still incorporating historical information.
Exponential Smoothing Methods
Exponential smoothing methods are another class of forecasting techniques that assign exponentially decreasing weights to past observations. These methods are particularly effective for capturing short-term fluctuations while still considering the overall trend in the data.
Single Exponential Smoothing
Single Exponential Smoothing assigns exponentially decreasing weights to past observations, with the most recent observations receiving higher weights. The forecast is calculated as a weighted average of the previous observation and the previous forecast.
Formula for Single Exponential Smoothing:
F_t+1 = α * x_t + (1 - α) * F_t
Where:
- F_t+1 is the forecast for the next time period.
- x_t is the observed value at time t.
- F_t is the forecast for the current time period.
- α is the smoothing parameter (0 < α < 1).
Double Exponential Smoothing (Holt's Method)
Double Exponential Smoothing, also known as Holt's Method, extends single exponential smoothing to capture both trend and seasonality in the data. It involves smoothing the level and trend components separately.
Triple Exponential Smoothing (Holt-Winters Method)
Triple Exponential Smoothing, or Holt-Winters Method, extends double exponential smoothing to incorporate seasonality into the forecast. It includes additional smoothing parameters for the seasonal component, allowing the model to capture seasonal patterns in the data.
Autoregressive Integrated Moving Average (ARIMA) Model
The Autoregressive Integrated Moving Average (ARIMA) model is a popular time series forecasting model that combines autoregressive (AR), differencing (I), and moving average (MA) components. ARIMA models can capture various time series patterns, including trends, seasonality, and irregular fluctuations.
The ARIMA model is denoted as ARIMA(p, d, q), where:
- p is the order of the autoregressive (AR) component.
- d is the degree of differencing required to achieve stationarity.
- q is the order of the moving average (MA) component.
ARIMA models are widely used for forecasting time series data in various domains, including finance, economics, and meteorology.
Seasonal ARIMA (SARIMA) Model
The Seasonal ARIMA (SARIMA) model extends the ARIMA framework to incorporate seasonal components in the data. SARIMA models are well-suited for time series data that exhibit seasonal patterns or fluctuations.
The SARIMA model is denoted as SARIMA(p, d, q)(P, D, Q)m, where:
- p, d, and q represent the non-seasonal AR, differencing, and MA components, respectively.
- P, D, and Q represent the seasonal AR, differencing, and MA components.
- m is the seasonal period.
By considering both non-seasonal and seasonal components, SARIMA models can provide more accurate forecasts for seasonal time series data.
Other Forecasting Models
In addition to the aforementioned methods, several other forecasting models and techniques exist, each with its advantages and applications:
- Seasonal Decomposition of Time Series (STL): STL decomposes time series data into seasonal, trend, and residual components, allowing for more flexible modeling and forecasting.
- Vector Autoregression (VAR): VAR models are used to analyze and forecast multivariate time series data by capturing the dependencies between multiple variables.
- Long Short-Term Memory (LSTM) Networks: LSTM networks are a type of recurrent neural network (RNN) capable of learning long-term dependencies in time series data, making them well-suited for sequential forecasting tasks.
Each forecasting model has strengths and weaknesses, and the choice depends on the specific characteristics of the time series data and the forecasting objectives. Experimentation and validation are essential to determining the most suitable model for a given forecasting task.
Time Series Model Evaluation and Selection
Ensuring the accuracy and reliability of time series forecasting models is paramount for making informed decisions and predictions. We'll introduce you to various evaluation techniques and criteria for selecting the most suitable forecasting model.
Performance Metrics for Time Series Forecasting
Performance metrics provide quantitative measures of a model's accuracy and effectiveness in predicting future values. Several metrics are commonly used to evaluate the performance of time series forecasting models:
- Mean Absolute Error (MAE): MAE measures the average absolute difference between the predicted and actual values. It provides a straightforward measure of forecasting accuracy, with lower values indicating better performance.
- Mean Squared Error (MSE): MSE calculates the average squared difference between the predicted and actual values. It penalizes larger errors more heavily than MAE, making it sensitive to outliers.
- Root Mean Squared Error (RMSE): RMSE is the square root of the MSE and provides a measure of the average magnitude of errors in the forecast. Like MSE, lower RMSE values indicate better model performance.
- Mean Absolute Percentage Error (MAPE): MAPE calculates the average percentage difference between the predicted and actual values relative to the actual values. It provides a measure of relative forecasting accuracy, making it helpful in comparing models across different datasets or scales.
Cross-Validation Techniques
Cross-validation is a critical step in assessing the generalizability and robustness of time series forecasting models. It involves splitting the data into training and validation sets and iteratively evaluating the model's performance on different subsets of the data.
Train-Test Split
The train-test split involves dividing the data into a training set, used to train the model, and a separate test set, used to evaluate the model's performance. The model is trained on historical data and then tested on unseen data to assess its ability to generalize to new observations.
K-Fold Cross-Validation
K-fold cross-validation partitions the data into K equal-sized subsets or folds. The model is trained K times, each time using K-1 folds for training and the remaining fold for validation. This process is repeated for each fold, and the performance metrics are averaged across all iterations to obtain an overall evaluation of the model.
Model Selection Criteria
Selecting the most appropriate forecasting model involves considering various factors, including the complexity of the model, its computational efficiency, and its ability to capture the underlying patterns in the data. Several criteria can guide the selection of a forecasting model:
- Akaike Information Criterion (AIC): AIC is a measure of the relative quality of a statistical model, balancing goodness of fit with model complexity. Lower AIC values indicate better model performance, with simpler models preferred over more complex ones.
- Bayesian Information Criterion (BIC): Similar to AIC, BIC penalizes model complexity to prevent overfitting. It provides a trade-off between model fit and parsimony, with lower BIC values indicating better model performance.
- Out-of-Sample Forecasting Accuracy: Ultimately, the most crucial criterion for model selection is its performance in accurately forecasting future values on unseen data. Models should be evaluated based on their ability to generalize to new observations and make accurate predictions in real-world scenarios.
By carefully evaluating performance metrics, employing robust cross-validation techniques, and considering model selection criteria, analysts can identify the most suitable forecasting model for their specific forecasting task and achieve more accurate and reliable predictions.
Time Series Analysis Examples
Examples play a crucial role in understanding the practical application of time series analysis techniques. So, let's delve into some real-world scenarios where time series analysis can be applied.
Stock Market Analysis
Time series analysis is extensively used in finance to analyze stock prices, predict market trends, and make investment decisions. Analysts utilize historical stock price data to identify patterns, detect anomalies, and develop predictive models for forecasting future prices.
Example: Analyzing a stock's historical performance using time series analysis techniques such as moving averages, exponential smoothing, and autoregressive models to identify potential buying or selling opportunities.
Demand Forecasting
Businesses use time series analysis to forecast demand for products or services, enabling efficient inventory management, resource allocation, and production planning. By analyzing historical sales data and external factors such as seasonality and economic trends, organizations can anticipate future demand and adjust their strategies.
Example: Using time series forecasting models to predict future demand for a product based on past sales data, promotional activities, and market trends, helping businesses optimize inventory levels and minimize stockouts or overstock situations.
Weather Forecasting
Meteorologists rely on time series analysis to forecast weather patterns, predict extreme events, and issue warnings for severe weather conditions. Meteorological agencies can provide accurate and timely forecasts to the public and emergency responders by analyzing historical weather data, satellite imagery, and atmospheric models.
Example: Employing time series analysis techniques such as autoregressive integrated moving average (ARIMA) models and seasonal decomposition to forecast temperature, precipitation, and wind patterns, assisting in disaster preparedness and risk mitigation efforts.
Health Monitoring
In healthcare, time series analysis is used to monitor patient health, predict disease outbreaks, and analyze medical data trends. Healthcare professionals analyze timestamped patient records, sensor data, and physiological measurements to detect anomalies, identify trends, and improve patient outcomes.
Example: Utilizing time series analysis to monitor vital signs such as heart rate, blood pressure, and glucose levels over time, identifying patterns indicative of potential health issues and enabling timely intervention and treatment.
Traffic Prediction
Urban planners and transportation agencies use time series analysis to forecast traffic congestion, optimize traffic flow, and plan infrastructure development projects. By analyzing historical traffic data, weather conditions, and events affecting traffic patterns, cities can improve traffic management and reduce congestion.
Example: Applying time series forecasting techniques to predict future traffic volumes on highways or urban roads based on historical traffic flow data, vehicle counts, and time-of-day patterns, facilitating efficient route planning and traffic management strategies.
These examples highlight the versatility and applicability of time series analysis across various domains, demonstrating its importance in decision-making, planning, and predictive modeling. By leveraging time series analysis techniques and tools, organizations can gain valuable insights, make informed decisions, and drive positive outcomes in their respective fields.
Advanced Topics in Time Series Analysis
Exploring advanced topics in time series analysis allows analysts to deepen their understanding and tackle more complex forecasting challenges. Here are several advanced techniques and methodologies for analyzing time series data.
Seasonal Adjustment Techniques
Seasonal adjustment techniques are essential for removing seasonal fluctuations from time series data, enabling analysts to focus on underlying trends and irregular variations. Several methods exist for seasonal adjustment:
- X-12-ARIMA: X-12-ARIMA is a widely used software tool developed by the U.S. Census Bureau for seasonal adjustment of time series data. It incorporates ARIMA modeling to estimate and remove seasonal components from the data.
- Seasonal Decomposition of Time Series (STL): Using a robust and flexible approach, STL decomposes time series data into seasonal, trend, and residual components. It allows analysts to analyze and model each component separately, providing more accurate forecasts.
Forecasting with Exogenous Variables
Incorporating exogenous variables, also known as external or predictor variables, into time series forecasting models can enhance predictive accuracy by capturing additional information that influences the target variable. Exogenous variables can include economic indicators, weather data, or other relevant factors.
- Vector Autoregression with Exogenous Variables (VARX): VARX models extend traditional VAR models by incorporating exogenous variables. They capture the dependencies between multiple time series variables while considering the influence of external factors.
- Dynamic Regression Models: Dynamic regression models incorporate both lagged values of the target variable and exogenous variables to predict future values. These models are particularly useful when the relationship between the target variable and external factors is complex or nonlinear.
Multivariate Time Series Analysis
Multivariate time series analysis involves analyzing and forecasting multiple time series variables simultaneously, taking into account the dependencies and interactions between them. This approach allows analysts to capture complex relationships and dependencies in the data.
- Vector Autoregression (VAR): VAR models are a popular choice for multivariate time series analysis. They model the joint dynamics of multiple variables using lagged values of all variables as predictors.
- Granger Causality Analysis: Granger causality analysis tests whether one time series variable can predict the future values of another variable, providing insights into causal relationships between variables.
Nonlinear Time Series Models
Nonlinear time series models capture complex and nonlinear relationships in the data, allowing for more flexible and accurate forecasting. These models are advantageous when the underlying dynamics of the time series are nonlinear or exhibit chaotic behavior.
- Nonlinear Autoregressive Exogenous (NARX) Models: NARX models extend traditional linear ARX models by introducing nonlinear transformations of the input and output variables. They can capture complex dependencies and patterns that linear models may miss.
- Neural Network Models: Neural network models, such as feedforward neural networks or recurrent neural networks (RNNs), can learn complex nonlinear relationships in time series data. They excel at capturing patterns and dependencies that are difficult to model using traditional linear approaches.
Time Series Clustering and Classification
Time series clustering and classification techniques aim to group similar time series data or classify them into predefined categories based on their patterns and characteristics. These techniques have applications in anomaly detection, pattern recognition, and segmentation.
- K-Means Clustering: K-Means clustering partitions time series data into K clusters based on similarity in their temporal patterns. It is useful for identifying groups of time series with similar behavior.
- Dynamic Time Warping (DTW): DTW is a distance-based method for measuring the similarity between time series data, accounting for variations in their temporal alignment. It is commonly used in time series clustering and classification tasks.
Exploring advanced topics in time series analysis opens up new avenues for understanding complex data patterns, improving forecasting accuracy, and gaining valuable insights into underlying trends and relationships. By incorporating these advanced techniques into their analytical toolkit, analysts can tackle a wide range of forecasting challenges and make more informed decisions based on time series data.
Conclusion for Time Series Analysis
Time series analysis is not just about crunching numbers; it's about uncovering stories hidden within data. Understanding how things change over time gives us valuable insights into the past, present, and future. So whether you're a seasoned analyst or just dipping your toes into the world of data, remember that every trend, every fluctuation has a story to tell. Keep exploring, keep analyzing, and let the data guide you toward better decisions and brighter futures.
But remember, while time series analysis offers a powerful toolkit for forecasting and prediction, it's not a crystal ball. The future is uncertain, and there are always surprises along the way. So embrace the uncertainty, learn from your data, and keep refining your models. After all, the beauty of time series analysis lies not in predicting the future with certainty but in understanding the patterns and trends shaping our world.
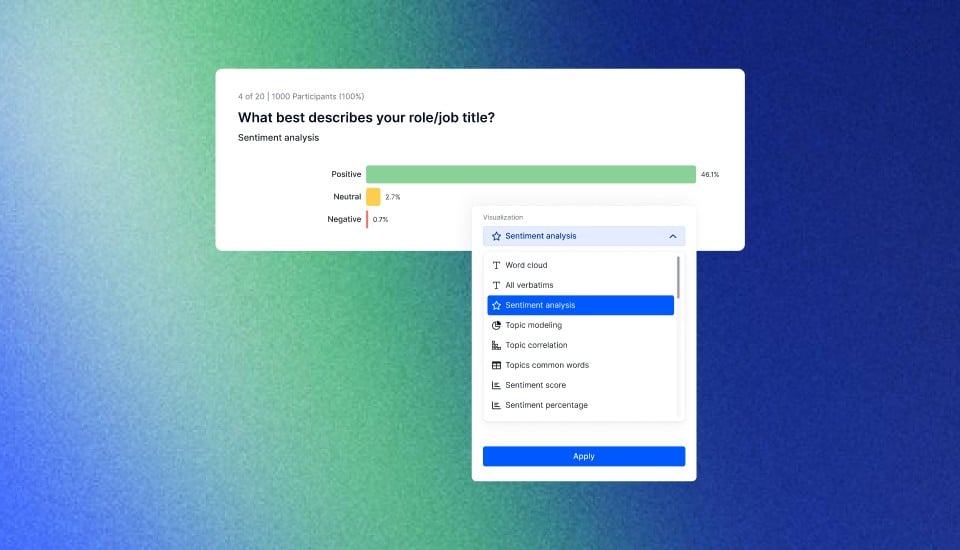
How to Conduct Time Series Analysis in Minutes?
Introducing Appinio, your go-to platform for conducting time series analysis with ease and speed. As a real-time market research platform, Appinio empowers companies to harness real-time consumer insights for smarter, data-driven decisions. With us, there's no need to navigate the complexities of research and technology – we handle the heavy lifting so you can focus on what truly matters: leveraging real-time consumer insights to drive business success.
Here's why Appinio stands out:
- From Questions to Insights in Minutes: Say goodbye to lengthy research processes. With Appinio, you can go from formulating your questions to obtaining actionable insights in a matter of minutes.
- Intuitive Platform for Everyone: You don't need a PhD in research to use Appinio. Our platform is designed to be intuitive and user-friendly so anyone can conduct market research effortlessly.
- Rapid Response Time: Need answers fast? With an average field time of less than 23 minutes for 1,000 respondents, Appinio delivers timely insights to fuel your decision-making process.
Get facts and figures 🧠
Want to see more data insights? Our free reports are just the right thing for you!