Appinio Research · 26.01.2026 · 31min Lesezeit

Hast du dich jemals gefragt, wie Unternehmen vorhersagen, welche Produkte du wahrscheinlich kaufen wirst, oder wie Gesundheitsdienstleister die Wahrscheinlichkeit bestimmter Krankheiten vorhersagen? Die prädiktive Modellierung ist der Schlüssel, um diese Geheimnisse zu lüften, indem Datenmuster analysiert werden, um fundierte Vorhersagen über zukünftige Ergebnisse zu treffen. Von der Erkennung betrügerischer Transaktionen im Finanzwesen bis hin zur Optimierung der Bestandsverwaltung im Einzelhandel spielt die prädiktive Modellierung in verschiedenen Branchen eine wichtige Rolle und hilft Unternehmen, intelligentere Entscheidungen zu treffen und ihre Effizienz zu steigern.
In diesem Leitfaden tauchen wir tief in die Welt der prädiktiven Modellierung ein und erforschen ihre Grundlagen, Techniken, realen Anwendungen und bewährten Verfahren. Ganz gleich, ob du ein Datenenthusiast bist, der neue Fähigkeiten erlernen möchte, oder ein Geschäftsmann, der nach Erkenntnissen sucht, um strategische Entscheidungen zu treffen - dieser Leitfaden wird dich mit dem Wissen und den Werkzeugen ausstatten, die du benötigst, um die Leistung der prädiktiven Modellierung effektiv zu nutzen.
Die prädiktive Modellierung analysiert historische Daten und Muster, um fundierte Vorhersagen über die Zukunft zu treffen. Sie ist entscheidend für die Optimierung von Geschäftsentscheidungen und die Steigerung der Effizienz in vielen Branchen. Von der Betrugserkennung im Finanzwesen bis zur Nachfrageprognose im Einzelhandel sind die Anwendungsmöglichkeiten vielfältig. Wichtig ist, saubere Daten zu nutzen, Modelle sorgfältig auszuwählen und sie kontinuierlich zu überwachen. Mit Appinio holst du dir die nötigen Konsumenten-Insights in Minuten, um deine Modelle mit aktuellen Daten zu versorgen und schneller verwertbare Ergebnisse zu erzielen.
Was ist prädiktive Modellierung?
Die prädiktive Modellierung ist eine Technik, die in der Datenwissenschaft und im maschinellen Lernen eingesetzt wird, um zukünftige Ergebnisse auf der Grundlage historischer Daten und vorhandener Muster vorherzusagen. Dabei werden mathematische Modelle entwickelt, die Beziehungen zwischen Variablen erfassen und diese nutzen, um Vorhersagen über unbekannte Datenpunkte zu treffen. Vorhersagemodelle können in verschiedenen Bereichen eingesetzt werden, z. B. im Finanzwesen, im Gesundheitswesen und im Marketing, um Trends vorherzusagen, Risiken zu erkennen und Entscheidungsprozesse zu steuern.
Bedeutung der prädiktiven Modellierung
- Verbesserte Entscheidungsfindung: Mit Hilfe von Prognosemodellen können Unternehmen datengestützte Entscheidungen treffen, indem sie Einblicke in zukünftige Trends und Ergebnisse erhalten.
- Risikomanagement: Durch die Vorhersage potenzieller Risiken und Chancen hilft die prädiktive Modellierung Unternehmen, Risiken zu mindern und Chancen effektiv zu nutzen.
- Optimierte Abläufe: Prognosemodelle können betriebliche Abläufe optimieren, indem sie die Nachfrage vorhersagen, die Lagerbestände optimieren und die Ressourcenzuweisung verbessern.
- Verbesserte Kundenbindung: Durch die Analyse des Kundenverhaltens und der Kundenpräferenzen können Unternehmen mit Hilfe von Prognosemodellen Marketingkampagnen personalisieren, die Kundenzufriedenheit verbessern und die Kundenbindungsrate erhöhen.
Anwendungen in verschiedenen Branchen
- Finanzwesen: Die prädiktive Modellierung wird im Finanzwesen zur Kreditwürdigkeitsprüfung, Betrugserkennung, Aktienkursprognose und zum Risikomanagement eingesetzt.
- Gesundheitswesen: Im Gesundheitswesen wird die prädiktive Modellierung für die Diagnose von Krankheiten, die Risikostratifizierung von Patienten, die Optimierung der Behandlung und die Zuweisung von Ressourcen im Gesundheitswesen eingesetzt.
- Marketing: Prognosemodelle helfen Marketingfachleuten bei der Kundensegmentierung, der Personalisierung von Marketingkampagnen, der Absatzprognose und der Optimierung von Werbeausgaben.
- Einzelhandel: Im Einzelhandel wird die prädiktive Modellierung für Nachfrageprognosen, Bestandsoptimierung, Vorhersage der Kundenabwanderung und Preisoptimierung eingesetzt.
- Fertigung: In der Fertigung werden Prognosemodelle für die vorausschauende Wartung, Qualitätskontrolle, Optimierung der Lieferkette und Produktionsplanung eingesetzt.
- Telekommunikation: Telekommunikationsunternehmen nutzen prädiktive Modelle für die Vorhersage der Kundenabwanderung, die Netzwerkoptimierung und die Ressourcenzuweisung.
- Energie: Im Energiesektor wird die prädiktive Modellierung für die Vorhersage des Energiebedarfs, die Wartung von Anlagen und die Optimierung des Energieverbrauchs eingesetzt.
Durch den Einsatz von Prognosemodellierungstechniken können Unternehmen wertvolle Erkenntnisse gewinnen, Entscheidungsprozesse verbessern und sich in der heutigen datengesteuerten Welt einen Wettbewerbsvorteil verschaffen.
Grundlagen der prädiktiven Modellierung
Die prädiktive Modellierung basiert auf einem soliden Fundament aus Datenverständnis, Vorverarbeitungstechniken, explorativer Datenanalyse (EDA) und Feature Engineering. Lassen Sie uns jeden dieser grundlegenden Aspekte näher betrachten, um dir das nötige Wissen zu vermitteln, das du für deine Reise in die prädiktive Modellierung benötigst.
Daten verstehen
Bevor du mit der Erstellung von Vorhersagemodellen beginnst, musst du die Daten, mit denen du arbeitest, genau verstehen. Dazu gehört nicht nur, dass du weißt, welche Art von Daten du hast, sondern auch, woher sie stammen und welche Eigenschaften sie aufweisen.
- Datentypen: Daten lassen sich grob in die Kategorien numerisch, kategorisch oder textuell einteilen. Die Kenntnis der Art deiner Daten ist für die Auswahl geeigneter Modellierungstechniken unerlässlich.
- Datenqualität: Die Bewertung der Qualität deiner Daten ist entscheidend. Dazu gehört die Identifizierung und Behandlung von fehlenden Werten, Ausreißern und Inkonsistenzen, um die Zuverlässigkeit deiner Modelle zu gewährleisten.
- Datenquelle: Die Kenntnis der Datenquelle und der Art und Weise, wie die Daten erhoben wurden, bietet einen Kontext und hilft dabei, während des Modellierungsprozesses fundierte Entscheidungen zu treffen.
Wenn du dich durch die Komplexität der Datenerfassung und -aufbereitung für die prädiktive Modellierung bewegst, solltest du den Einsatz leistungsstarker Tools wie Appinio für eine nahtlose Datenerfassung in Betracht ziehen. Mit Appinio kannst du mühelos Echtzeit-Konsumenteneinblicke sammeln und so deine Datensätze anreichern und die Genauigkeit deiner Vorhersagemodelle verbessern.
Buche unverbindlich eine Demo, um zu sehen, wie Appinio deinen Datenerfassungsprozess rationalisieren und deine Bemühungen um Vorhersagemodelle verbessern kann!
Techniken zur Vorverarbeitung von Daten
Die Datenvorverarbeitung ist ein wichtiger Schritt bei der prädiktiven Modellierung, um die Rohdaten für die Analyse und Modellierung vorzubereiten. In dieser Phase werden verschiedene Techniken zur Bereinigung und Umwandlung der Daten eingesetzt.
- Datenbereinigung: Hierbei werden Fehler in den Daten, wie fehlende Werte, Duplikate oder Ungenauigkeiten, entfernt oder korrigiert. Imputationsmethoden können verwendet werden, um fehlende Werte auf der Grundlage statistischer Maße oder von Fachwissen aufzufüllen.
- Datenumwandlung: Daten müssen oft transformiert werden, um sie für die Modellierung geeignet zu machen. Dazu gehören die Kodierung kategorischer Variablen in numerische Darstellungen, die Skalierung numerischer Merkmale auf einen gemeinsamen Bereich und die Behandlung von Schiefe oder Nicht-Normalität durch Transformationen wie Log oder Box-Cox.
- Merkmalstechnik: Beim Feature-Engineering werden neue Merkmale erstellt oder bestehende Merkmale transformiert, um die Vorhersagekraft des Modells zu verbessern. Dies kann die Erstellung von Interaktionsterms, die Ableitung neuer Merkmale aus vorhandenen oder die Kodierung zeitlicher Informationen beinhalten.
Explorative Datenanalyse (EDA)
Die explorative Datenanalyse (EDA) ist ein wichtiger Schritt, bei dem die Daten visuell untersucht und analysiert werden, um Muster, Trends und Beziehungen aufzudecken. EDA hilft nicht nur, die Daten besser zu verstehen, sondern dient auch als Grundlage für nachfolgende Modellierungsentscheidungen.
- Zusammenfassende Statistik: Berechne deskriptive Statistiken wie Mittelwert, Median, Varianz und Quartile, um die zentrale Tendenz und Streuung der Daten zusammenzufassen.
- Datenvisualisierung: Visualisierungen wie Histogramme, Boxplots, Streudiagramme und Heatmaps bieten Einblicke in die Verteilung und die Beziehungen zwischen Variablen.
- Korrelationsanalyse: Identifiziere Korrelationen zwischen Variablen, um zu verstehen, wie sie miteinander in Beziehung stehen. Korrelationsmatrizen oder Streudiagramm-Matrizen können zur Visualisierung paarweiser Beziehungen verwendet werden.
Merkmalstechnik
Die Entwicklung von Merkmalen ist ein wichtiger Aspekt der prädiktiven Modellierung, da sich die Qualität der Merkmale direkt auf die Leistung des Modells auswirkt. Effektives Feature-Engineering beinhaltet die Erstellung neuer Features oder die Umwandlung bestehender Features, um relevante Informationen und Muster in den Daten zu erfassen.
- Erstellung von Merkmalen: Die Generierung neuer Merkmale durch Techniken wie Binning, polynomiale Merkmale oder bereichsspezifische Transformationen kann die Vorhersagekraft des Modells verbessern.
- Auswahl von Merkmalen: Die Auswahl der relevantesten Merkmale ist entscheidend für die Einfachheit und Leistungsfähigkeit des Modells. Techniken wie die univariate Merkmalsauswahl, die rekursive Merkmalseliminierung oder die modellbasierte Merkmalsauswahl können eingesetzt werden.
- Dimensionalitätsreduzierung: Hochdimensionale Daten können eine Herausforderung für die prädiktive Modellierung darstellen. Techniken zur Dimensionalitätsreduktion wie die Hauptkomponentenanalyse (PCA) oder t-distributed Stochastic Neighbor Embedding (t-SNE) können dazu beitragen, die Anzahl der Merkmale zu reduzieren und gleichzeitig wesentliche Informationen zu erhalten.
Wenn du diese grundlegenden Konzepte und Techniken beherrschst, bist du gut gerüstet, um die Herausforderungen der prädiktiven Modellierung zu meistern und verwertbare Erkenntnisse aus deinen Daten zu gewinnen.
Modellauswahl und -auswertung
Die Auswahl des richtigen Prognosemodells und die Bewertung seiner Leistung sind entscheidende Schritte im Prozess der Prognosemodellierung. Lass uns die verschiedenen Aspekte der Modellauswahl und -bewertung untersuchen, um dir zu helfen, fundierte Entscheidungen zu treffen und die Effektivität deiner Vorhersagemodelle zu gewährleisten.
Arten von Prognosemodellen
Die prädiktive Modellierung umfasst ein breites Spektrum an Algorithmen und Techniken, die sich jeweils für unterschiedliche Arten von Daten und Vorhersageaufgaben eignen. Ein Verständnis der verschiedenen Arten von Vorhersagemodellen kann dir helfen, das für deine spezifische Anwendung am besten geeignete Modell auszuwählen.
- Regressionsmodelle: Regressionsmodelle werden verwendet, wenn die Zielvariable kontinuierlich ist. Sie zielen auf die Vorhersage eines numerischen Wertes auf der Grundlage von Eingabemerkmalen ab. Beispiele sind die lineare Regression, die polynomiale Regression und die Support-Vektor-Regression.
- Klassifizierungsmodelle: Klassifizierungsmodelle werden eingesetzt, wenn die Zielvariable kategorisch ist und zwei oder mehr Klassen umfasst. Diese Modelle ordnen den Eingabeinstanzen auf der Grundlage ihrer Merkmale Klassenetiketten zu. Zu den gängigen Klassifizierungsalgorithmen gehören logistische Regression, Entscheidungsbäume, Random Forests und Support Vector Machines.
- Clustering-Modelle: Clustering-Modelle sind unbeaufsichtigte Lerntechniken, die dazu dienen, ähnliche Datenpunkte auf der Grundlage ihrer Merkmale zu gruppieren. K-Means-Clustering und hierarchisches Clustering sind beliebte Clustering-Algorithmen, die in der prädiktiven Modellierung eingesetzt werden.
- Zeitreihenmodelle: Zeitreihenmodelle sind spezielle Algorithmen zur Analyse und Vorhersage zeitabhängiger Daten. Sie werden häufig in den Bereichen Finanzen, Wirtschaft und Wettervorhersage eingesetzt, um zukünftige Werte auf der Grundlage historischer Muster vorherzusagen.
Kriterien für die Modellauswahl
Bei der Auswahl eines Prognosemodells für deine Daten und deinen Problembereich müssen verschiedene Faktoren berücksichtigt werden, um eine optimale Leistung und Interpretierbarkeit zu gewährleisten.
- Genauigkeit: Das Hauptziel der prädiktiven Modellierung besteht darin, Modelle zu erstellen, die genaue Vorhersagen für ungesehene Daten machen. Modelle mit höherer Genauigkeit werden bevorzugt, aber es ist wichtig, eine Überanpassung der Trainingsdaten zu vermeiden.
- Interpretierbarkeit: Je nach Anwendung kann die Interpretierbarkeit des Modells entscheidend sein. Einfache Modelle wie die lineare Regression sind leicht zu interpretieren, können aber im Vergleich zu komplexeren Modellen wie neuronalen Netzen zu Lasten der Vorhersageleistung gehen.
- Skalierbarkeit: Berücksichtige die Skalierbarkeit des Modells, um große Datensätze und Echtzeit-Vorhersageaufgaben zu bewältigen. Einige Algorithmen, wie z. B. Support-Vektor-Maschinen, haben möglicherweise Probleme mit der Skalierbarkeit im Vergleich zu einfacheren Modellen wie Entscheidungsbäumen.
- Domänenwissen: Die Nutzung von Fachwissen kann bei der Modellauswahl und der Entwicklung von Merkmalen hilfreich sein. Das Verständnis der zugrunde liegenden Prozesse und Beziehungen in den Daten kann die Auswahl geeigneter Algorithmen und Merkmale leiten.
Techniken der Kreuzvalidierung
Die Kreuzvalidierung ist eine robuste Methode zur Schätzung der Leistung von Vorhersagemodellen und zur Auswahl von Hyperparametern, ohne dass ein separater Validierungssatz erforderlich ist. In der Praxis werden häufig mehrere Kreuzvalidierungsverfahren eingesetzt.
- K-fache Kreuzvalidierung: Bei der K-fachen Kreuzvalidierung wird der Datensatz in K Teilmengen oder Faltungen unterteilt. Das Modell wird auf K-1 Falten trainiert und auf der verbleibenden Falte bewertet, wobei dieser Vorgang K Mal wiederholt wird. Die Leistungsmetriken werden dann über die K Iterationen gemittelt.
- Leave-One-Out Cross-Validation (LOOCV): LOOCV ist ein Spezialfall der K-fachen Kreuzvalidierung, wobei K der Anzahl der Instanzen im Datensatz entspricht. Bei jeder Iteration wird ein Datenpunkt als Validierungssatz ausgelassen, und das Modell wird auf den verbleibenden Datenpunkten trainiert.
- Stratifizierte Kreuzvalidierung: Die stratifizierte Kreuzvalidierung stellt sicher, dass jeder Fold eine proportionale Repräsentation der verschiedenen Klassen im Datensatz enthält, was sie besonders für unausgewogene Klassifizierungsaufgaben nützlich macht.
Leistungsmetriken
Die Bewertung der Leistung von Vorhersagemodellen erfordert die Verwendung geeigneter Metriken, die die Vorhersagegenauigkeit und Effektivität des Modells quantifizieren.
- Genauigkeit: Die Genauigkeit misst den Anteil der korrekt vorhergesagten Instanzen an der Gesamtzahl der Instanzen. Obwohl die Genauigkeit eine Standardmetrik ist, eignet sie sich möglicherweise nicht für unausgewogene Datensätze, bei denen eine Klasse deutlich häufiger vorkommt als die anderen.
- Präzision und Rückruf: Die Präzision misst den Anteil wahrer positiver Vorhersagen an allen positiven Vorhersagen, während der Rückruf den Anteil wahrer positiver Vorhersagen an allen tatsächlich positiven Instanzen misst. Precision und Recall sind besonders nützlich für die Bewertung von Klassifizierungsmodellen, vor allem in Szenarien, in denen falsch-positive oder falsch-negative Vorhersagen unterschiedliche Auswirkungen haben.
- F1-Punktzahl: Der F1-Score ist das harmonische Mittel aus Precision und Recall und bietet ein Gleichgewicht zwischen den beiden Metriken. Er ist besonders nützlich für unausgewogene Datensätze, bei denen die Genauigkeit allein irreführend sein kann.
Wenn du die verschiedenen Arten von Vorhersagemodellen, die Kriterien für die Modellauswahl, die Kreuzvalidierungstechniken und die Leistungsmetriken verstehst, kannst du die am besten geeigneten Modelle für deine Vorhersagemodellierungsaufgaben effektiv bewerten und auswählen.
Wie erstellt man ein prädiktives Modell?
Die Erstellung von Vorhersagemodellen umfasst die Auswahl geeigneter Algorithmen und Techniken zur Datenanalyse und Erstellung von Vorhersagen. Im Folgenden werden die verschiedenen Ansätze zur Erstellung von Vorhersagemodellen untersucht, darunter Algorithmen für überwachtes Lernen, Algorithmen für unüberwachtes Lernen und Ensemble-Methoden.
Überwachte Lernalgorithmen
Algorithmen des überwachten Lernens werden auf markierten Daten trainiert, bei denen die Zielvariable bekannt ist, und das Ziel besteht darin, eine Zuordnung von Eingabemerkmalen zu der Zielvariablen zu lernen. Diese Algorithmen werden häufig für Vorhersage- und Klassifizierungsaufgaben verwendet.
Regressionsmodelle
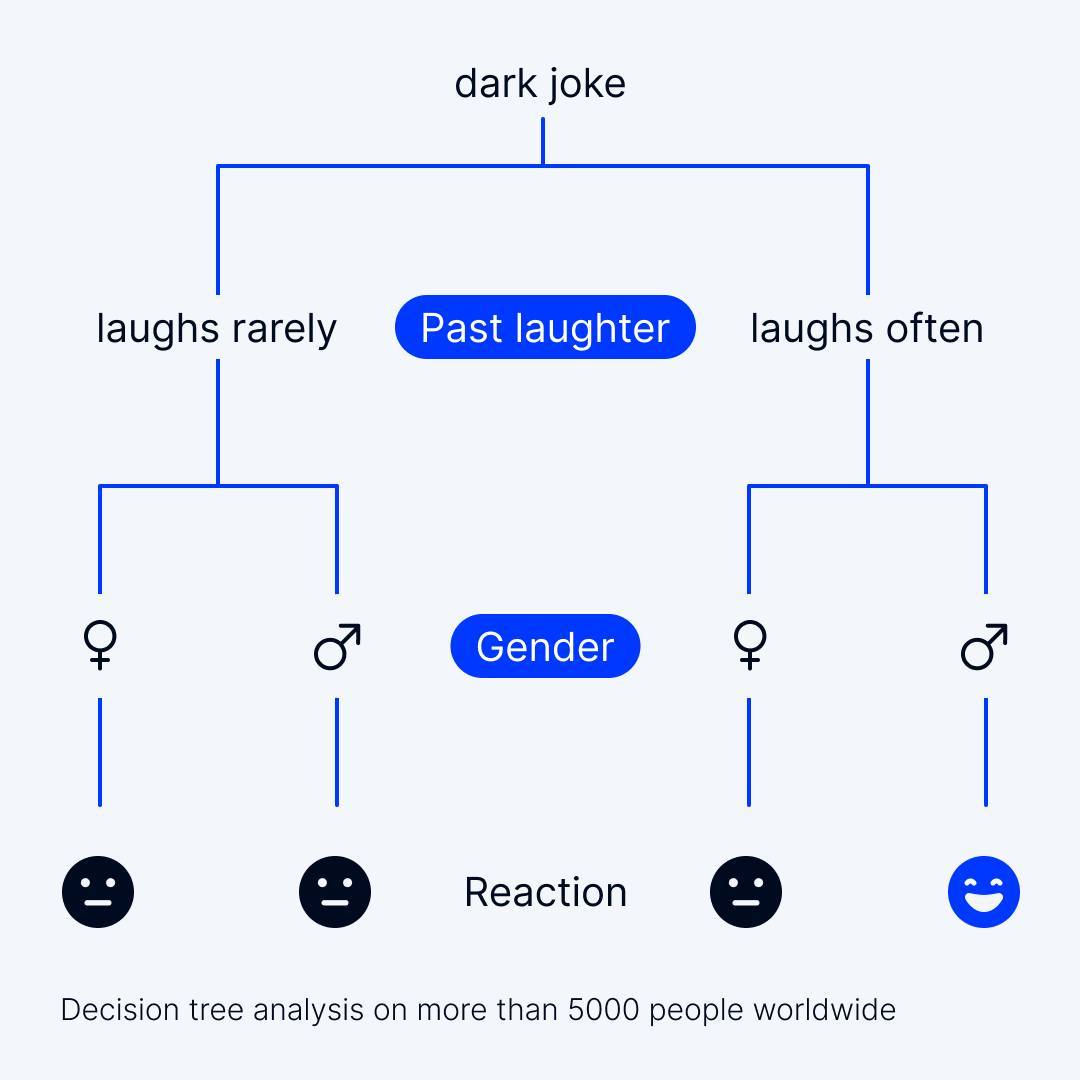
Regressionsmodelle werden verwendet, wenn die Zielvariable kontinuierlich und numerisch ist. Diese Modelle zielen darauf ab, einen numerischen Wert auf der Grundlage von Eingangsmerkmalen vorherzusagen. Beliebte Regressionsalgorithmen sind:
- Lineare Regression: Die lineare Regression modelliert die Beziehung zwischen den Eingabemerkmalen und der Zielvariablen anhand einer linearen Gleichung. Sie ist einfach, interpretierbar und dient oft als Basismodell.
- Entscheidungsbäume: Entscheidungsbäume partitionieren den Merkmalsraum in hierarchische Entscheidungsregeln auf der Grundlage von Merkmalswerten. Sie sind intuitiv und leicht zu interpretieren, können aber zu einer Überanpassung führen.
- Support-Vektor-Regression (SVR): SVR ist eine Variante der Support-Vektor-Maschinen (SVM), die für Regressionsaufgaben verwendet wird. Sie zielt darauf ab, die Hyperebene zu finden, die den Spielraum maximiert und gleichzeitig den Fehler minimiert.
Klassifizierungsmodelle
Klassifizierungsmodelle werden verwendet, wenn die Zielvariable kategorisch ist und zwei oder mehr Klassen umfasst. Diese Modelle weisen den Eingabeinstanzen auf der Grundlage ihrer Merkmale Klassenbezeichnungen zu. Zu den gängigen Klassifizierungsalgorithmen gehören:
- Logistische Regression: Die logistische Regression wird für binäre Klassifizierungsaufgaben verwendet, bei denen die Zielvariable zwei mögliche Ergebnisse hat. Sie modelliert die Wahrscheinlichkeit der Zugehörigkeit zu einer bestimmten Klasse mithilfe der logistischen Funktion.
- Zufalls-Wald: Random Forest ist eine Ensemble-Lernmethode, die mehrere Entscheidungsbäume kombiniert, um die Vorhersageleistung zu verbessern. Sie reduziert die Überanpassung und ist robust gegenüber Rauschen und Ausreißern.
- Gradient Boosting Machines (GBM): GBM baut sequentiell eine Reihe schwacher Lerner auf, die sich jeweils auf die Fehler ihrer Vorgänger konzentrieren. Sie kombiniert deren Vorhersagen, um eine endgültige Vorhersage zu treffen und eine hohe Genauigkeit zu erreichen.
Algorithmen für unüberwachtes Lernen
Algorithmen für unüberwachtes Lernen werden auf nicht beschrifteten Daten trainiert, mit dem Ziel, versteckte Muster oder Strukturen in den Daten zu entdecken. Diese Algorithmen werden häufig für Clustering, Dimensionalitätsreduktion und die Erkennung von Anomalien verwendet.
Clustering-Modelle
Clustering-Modelle teilen die Daten auf der Grundlage der Ähnlichkeit der Instanzen in Gruppen oder Cluster auf. Jedes Cluster enthält Datenpunkte, die einander ähnlicher sind als denen in anderen Clustern. Zu den gängigen Clustering-Algorithmen gehören:
- K-Means-Clustering: K-Means ist ein Partitionierungsalgorithmus, der die Daten in K Cluster aufteilt, indem er die Varianz innerhalb eines Clusters minimiert. Er ist effizient und einfach zu implementieren, erfordert aber eine vorherige Festlegung der Anzahl der Cluster.
- Hierarchisches Clustering: Hierarchisches Clustering baut eine baumartige Hierarchie von Clustern auf, indem es Cluster auf der Grundlage ihrer Nähe rekursiv zusammenführt oder aufteilt. Die Anzahl der Cluster muss nicht im Voraus festgelegt werden, und die Beziehungen zwischen den Clustern lassen sich besser visualisieren.
Dimensionalitätsreduzierung
Techniken zur Dimensionalitätsreduzierung zielen darauf ab, die Anzahl der Merkmale im Datensatz zu reduzieren und gleichzeitig die wesentlichen Informationen zu erhalten. Dies kann dazu beitragen, den Rechenaufwand zu verringern, Rauschen zu entfernen und hochdimensionale Daten zu visualisieren. Zu den gängigen Algorithmen zur Dimensionalitätsreduktion gehören:
- Principal Component Analysis (PCA): Die PCA ist ein lineares Verfahren zur Dimensionalitätsreduktion, das die Hauptkomponenten der Daten identifiziert, die die Richtungen der maximalen Varianz erfassen. Sie projiziert die Daten auf einen niedriger-dimensionalen Unterraum, wobei der größte Teil der Variabilität erhalten bleibt.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): t-SNE ist ein nichtlineares Verfahren zur Dimensionalitätsreduktion, bei dem die Erhaltung der lokalen Struktur der Daten im Vordergrund steht. Sie wird häufig zur Visualisierung hochdimensionaler Daten im niedrigdimensionalen Raum verwendet, insbesondere bei der Clustering-Analyse.
Ensemble-Methoden
Ensemble-Methoden kombinieren mehrere Basismodelle, um die Vorhersageleistung und Robustheit zu verbessern. Durch die Aggregation der Vorhersagen verschiedener Modelle können Ensemble-Methoden eine höhere Genauigkeit erreichen als einzelne Modelle.
- Bagging (Bootstrap-Aggregation): Beim Bagging werden mehrere Instanzen desselben Basismodells auf verschiedenen Bootstrap-Stichproben der Trainingsdaten trainiert und ihre Vorhersagen durch Mittelwertbildung (für Regression) oder Abstimmung (für Klassifizierung) aggregiert.
- Boosten: Beim Boosting wird nacheinander eine Reihe schwacher Lerner erstellt, wobei sich jeder Lerner auf die Fehler seiner Vorgänger konzentriert. Gradient Boosting und AdaBoost sind beliebte Boosting-Algorithmen, die in der prädiktiven Modellierung eingesetzt werden.
- Stapeln: Beim Stacking werden die Vorhersagen mehrerer Basismodelle mithilfe eines Meta-Learners, häufig eines einfachen linearen Modells, kombiniert. Es nutzt die komplementären Stärken der verschiedenen Modelle, um die Vorhersageleistung weiter zu verbessern.
Durch den Einsatz von Algorithmen für überwachtes und unüberwachtes Lernen sowie Ensemble-Methoden kannst du leistungsstarke Vorhersagemodelle erstellen, die genaue Vorhersagen treffen und wertvolle Erkenntnisse aus deinen Daten aufdecken können.
Beispiele für prädiktive Modellierung
Um die praktischen Anwendungen der prädiktiven Modellierung besser zu verstehen, wollen wir einige Beispiele aus der Praxis betrachten, die zeigen, wie die prädiktive Modellierung erfolgreich zur Lösung komplexer Probleme und zur Unterstützung von Entscheidungsprozessen eingesetzt wurde.
Vorhersage der Kundenabwanderung in der Telekommunikation
Telekommunikationsunternehmen nutzen die prädiktive Modellierung, um Kunden zu identifizieren, bei denen die Wahrscheinlichkeit besteht, dass sie ihr Abonnement kündigen. Durch die Analyse von Kundenverhalten, Nutzungsmustern und demografischen Daten können Telekommunikationsunternehmen Vorhersagemodelle erstellen, um das Abwanderungsrisiko zu prognostizieren und gezielte Kundenbindungsstrategien zu implementieren, z. B. personalisierte Angebote oder proaktive Kundendienstmaßnahmen, um die Abwanderungsrate zu senken und die Kundenzufriedenheit zu verbessern.
Betrugserkennung im Finanzwesen
Banken und Finanzinstitute nutzen prädiktive Modelle, um betrügerische Transaktionen und Aktivitäten zu erkennen. Durch die Analyse historischer Transaktionsdaten, des Benutzerverhaltens und anderer relevanter Merkmale können Vorhersagemodelle anomale Muster erkennen, die auf betrügerisches Verhalten hindeuten, z. B. unberechtigter Zugriff, Identitätsdiebstahl oder ungewöhnliche Ausgabenmuster. Betrugserkennungsmodelle helfen Finanzinstituten, Verluste zu minimieren, das Vermögen ihrer Kunden zu schützen und das Vertrauen in ihre Dienstleistungen zu erhalten.
Risikovorhersage im Gesundheitswesen
Die prädiktive Modellierung spielt im Gesundheitswesen eine entscheidende Rolle bei der Risikovorhersage und der Diagnose von Krankheiten. Beispielsweise können Vorhersagemodelle elektronische Gesundheitsakten, medizinische Bildgebungsdaten und genetische Informationen analysieren, um das Risiko von Patienten für die Entwicklung bestimmter Krankheiten oder Zustände wie Diabetes, Herz-Kreislauf-Erkrankungen oder Krebs zu bewerten. Diese Modelle ermöglichen ein frühzeitiges Eingreifen, personalisierte Behandlungspläne und bessere Patientenergebnisse, indem sie Risikopersonen identifizieren und Präventivmaßnahmen priorisieren.
Nachfrageprognose im Einzelhandel
Einzelhändler nutzen prädiktive Modelle, um die künftige Nachfrage nach Produkten zu prognostizieren und das Bestandsmanagement und die Abläufe in der Lieferkette zu optimieren. Durch die Analyse historischer Verkaufsdaten, saisonaler Muster, Werbeaktivitäten und externer Faktoren wie Wetter oder wirtschaftliche Bedingungen können Prognosemodelle künftige Verkaufsmengen genau vorhersagen. Nachfrageprognosemodelle helfen Einzelhändlern, Fehlbestände zu minimieren, überschüssige Bestände zu reduzieren und die allgemeine betriebliche Effizienz und Rentabilität zu verbessern.
Diese Beispiele veranschaulichen die vielfältigen Anwendungsmöglichkeiten von Prognosemodellen in verschiedenen Branchen und zeigen, dass sie das Potenzial haben, verwertbare Erkenntnisse zu liefern, die Entscheidungsfindung zu verbessern und die Geschäftsergebnisse zu steigern.
Modellinterpretation und -implementierung
Nach der Erstellung von Vorhersagemodellen geht es in den nächsten Schritten darum, die Ergebnisse effektiv zu interpretieren und in realen Anwendungen einzusetzen. Im Folgenden erfährst du, wie die Modellergebnisse zu interpretieren sind, welche Strategien für den Einsatz von Modellen zur Verfügung stehen und wie wichtig die Überwachung und Wartung ist.
Interpretation von Modellergebnissen
Die Interpretation von Modellergebnissen ist wichtig, um zu verstehen, wie dein Modell Vorhersagen trifft, und um seine Erkenntnisse effektiv zu kommunizieren. Verschiedene Techniken können dir bei der Analyse der Ergebnisse deiner Prognosemodelle helfen.
- Wichtigkeit der Merkmale: Zu verstehen, welche Merkmale den größten Einfluss auf die Vorhersagen haben, kann wertvolle Einblicke in die zugrunde liegenden Beziehungen in den Daten liefern. Techniken wie die Permutationsbedeutung, SHAP-Werte oder Koeffizienten in linearen Modellen können bei der Quantifizierung der Merkmalsbedeutung helfen.
- Partielle Abhängigkeitsdiagramme: Partielle Abhängigkeitsdiagramme visualisieren die Beziehung zwischen einem Merkmal und dem vorhergesagten Ergebnis, wobei die Werte anderer Merkmale marginalisiert werden. Mit ihrer Hilfe lässt sich feststellen, wie sich Änderungen an einem bestimmten Merkmal auf die Vorhersagen des Modells auswirken.
- Techniken zur Modellerläuterung: Modellerklärungsverfahren wie LIME (Local Interpretable Model-agnostic Explanations) oder SHAP (SHapley Additive exPlanations) liefern lokale oder globale Erklärungen für einzelne Vorhersagen und helfen so, den Entscheidungsprozess komplexer Modelle wie neuronaler Netze zu verstehen.
Strategien für den Einsatz von Modellen
Der Einsatz von Vorhersagemodellen in Produktionsumgebungen erfordert eine sorgfältige Planung und die Berücksichtigung verschiedener Faktoren, darunter Skalierbarkeit, Zuverlässigkeit und Integration in bestehende Systeme.
- Skalierbarkeit: Stelle sicher, dass dein eingesetztes Modell große Mengen an eingehenden Daten und Anfragen effizient verarbeiten kann. Dies kann die Bereitstellung des Modells auf einer skalierbaren Infrastruktur wie Cloud-Plattformen oder die Verwendung von Techniken wie Modellparallelität beinhalten.
- Echtzeit vs. Batch-Verarbeitung: Entscheide, ob dein Modell Echtzeit-Vorhersagen machen muss oder ob eine Stapelverarbeitung ausreicht. Echtzeitanwendungen erfordern geringe Latenzzeiten und einen hohen Durchsatz, während die Stapelverarbeitung die Offline-Analyse großer Datensätze ermöglicht.
- API-Integration: Stelle dein Modell als API (Application Programming Interface) zur Verfügung, damit andere Systeme und Anwendungen mit ihm interagieren können. RESTful-APIs werden häufig für diesen Zweck verwendet und bieten eine standardisierte Möglichkeit für Clients, mit dem Modell zu kommunizieren.
- Modellversionierung: Implementiere ein System zur Versionierung deiner Modelle, um Änderungen zu verfolgen und die Reproduzierbarkeit zu gewährleisten. So kannst du bei Bedarf auf frühere Versionen zurückgreifen und die Konsistenz über verschiedene Umgebungen hinweg aufrechterhalten.
Überwachung und Wartung
Nach der Bereitstellung müssen Vorhersagemodelle laufend überwacht und gewartet werden, um sicherzustellen, dass sie weiterhin optimal funktionieren und im Laufe der Zeit relevant bleiben.
- Überwachung der Leistung: Überwache die Leistung deines eingesetzten Modells regelmäßig, um eine Verschlechterung der Genauigkeit oder Vorhersagekraft zu erkennen. Richte automatische Warnungen für Anomalien oder Abweichungen vom erwarteten Verhalten ein.
- Erkennung von Datendrift: Eine Datendrift tritt auf, wenn sich die Verteilung der eingehenden Daten im Laufe der Zeit ändert, was zu einer Diskrepanz zwischen den Trainings- und Einsatzdaten führt. Implementiere Mechanismen zur Erkennung von Datendrifts, um diese Änderungen umgehend zu erkennen und zu beheben.
- Modell neu trainieren: Trainiere dein Modell regelmäßig mit neuen Daten, um sicherzustellen, dass es auf dem neuesten Stand bleibt und sich an die sich entwickelnden Muster und Trends in den Daten anpasst. Lege einen Zeitplan für die Umschulung fest, der sich nach der Geschwindigkeit der Datenänderungen und der Wichtigkeit des Modells richtet.
- Feedback-Schleifen: Integriere Feedback-Schleifen in deine Bereitstellungspipeline, um Benutzerfeedback und Ground-Truth-Labels für Vorhersagen zu sammeln. Dieses Feedback kann zur kontinuierlichen Verbesserung des Modells und zur Behebung von Verzerrungen oder Fehlern verwendet werden.
Durch die effektive Interpretation von Modellergebnissen, den Einsatz von Modellen mit robusten Strategien und die Implementierung von Überwachungs- und Wartungspraktiken kannst du den erfolgreichen Einsatz und die langfristige Effektivität deiner Prognosemodelle in realen Anwendungen sicherstellen.
Tools und Bibliotheken für die prädiktive Modellierung
Die Auswahl der richtigen Software und Bibliotheken ist für die effektive Implementierung von Prognosemodellierungslösungen von entscheidender Bedeutung. Es stehen zahlreiche Tools zur Verfügung, die jeweils einzigartige Funktionen und Möglichkeiten bieten. Im Folgenden werden einige der gängigen Software- und Bibliothekstools vorgestellt, die bei der prädiktiven Modellierung eingesetzt werden.
Python-Bibliotheken
Python hat sich dank seines umfangreichen Ökosystems an Bibliotheken und Frameworks als dominierende Sprache im Bereich der Datenwissenschaft und des maschinellen Lernens etabliert. Zu den am häufigsten verwendeten Python-Bibliotheken für die prädiktive Modellierung gehören:
- scikit-learn: scikit-learn ist eine umfassende Bibliothek für maschinelles Lernen, die einfache und effiziente Data-Mining- und Analysetools bereitstellt. Sie bietet verschiedene Algorithmen für Klassifizierung, Regression, Clustering, Dimensionalitätsreduktion und Modellauswahl.
- TensorFlow: TensorFlow wurde von Google entwickelt und ist ein Open-Source-Framework für maschinelles Lernen, das häufig für die Erstellung und das Training von Deep-Learning-Modellen verwendet wird. Es bietet eine flexible Architektur für die Implementierung verschiedener neuronaler Netzwerkarchitekturen und lässt sich von einzelnen Geräten bis hin zu verteilten Systemen skalieren.
- PyTorch: PyTorch ist ein weiteres beliebtes Deep-Learning-Framework, das für seinen dynamischen Berechnungsgraphen und seine Benutzerfreundlichkeit bekannt ist. Es bietet ein reichhaltiges Ökosystem von Bibliotheken und Tools für den Aufbau und das Training neuronaler Netze und unterstützt sowohl Forschungs- als auch Produktionseinsätze.
- XGBoost und LightGBM: XGBoost und LightGBM sind Gradient-Boosting-Bibliotheken, die für ihre hohe Leistung und Skalierbarkeit bekannt sind. Sie werden häufig für die Erstellung von Ensemble-Modellen verwendet und erzielen bei Prognosemodellierungswettbewerben und realen Anwendungen Spitzenergebnisse.
R-Pakete
R ist eine Programmiersprache und -umgebung, die speziell für statistische Berechnungen und Grafiken entwickelt wurde. Sie bietet eine umfangreiche Sammlung von Paketen für verschiedene statistische und prädiktive Modellierungsaufgaben. Einige beliebte R-Pakete für die prädiktive Modellierung sind:
- caret: caret (Classification And REgression Training) ist ein umfassendes Paket für die Erstellung und Auswertung von Vorhersagemodellen in R. Es bietet eine einheitliche Schnittstelle für das Training und die Abstimmung einer breiten Palette von Algorithmen für maschinelles Lernen.
- randomForest: randomForest ist ein R-Paket, das den Random-Forest-Algorithmus für Klassifizierungs- und Regressionsaufgaben implementiert. Es konstruiert ein Ensemble von Entscheidungsbäumen und aggregiert deren Vorhersagen, um die Genauigkeit und Robustheit zu verbessern.
- glmnet: glmnet ist ein Paket zur Anpassung verallgemeinerter linearer Modelle mit Lasso- oder Elastic-Net-Regularisierung. Es ist nützlich für hochdimensionale Daten und Merkmalsauswahlaufgaben, bei denen die Anzahl der Prädiktoren die Anzahl der Beobachtungen übersteigt.
- keras: keras ist eine R-Schnittstelle zur Deep-Learning-Bibliothek Keras, die eine High-Level-API für den Aufbau und das Training neuronaler Netze bietet. Sie bietet eine benutzerfreundliche Schnittstelle und eine nahtlose Integration mit dem TensorFlow-Backend zur Entwicklung von Deep-Learning-Modellen.
Andere Tools und Plattformen
Zusätzlich zu den Python- und R-Bibliotheken bieten mehrere andere Tools und Plattformen Funktionen für die prädiktive Modellierung:
- Microsoft Azure Machine Learning: Azure Machine Learning ist eine Cloud-basierte Plattform zum Erstellen, Trainieren und Bereitstellen von Modellen für maschinelles Lernen in großem Umfang. Sie bietet eine Reihe von Tools und Diensten für die Datenvorbereitung, Modellentwicklung und Operationalisierung.
- Amazon SageMaker: Amazon SageMaker ist ein vollständig verwalteter Service, der es Entwicklern und Datenwissenschaftlern ermöglicht, Modelle für maschinelles Lernen schnell und einfach zu erstellen, zu trainieren und bereitzustellen. Er bietet integrierte Algorithmen, vorgefertigte Notebooks und eine skalierbare Infrastruktur für End-to-End-ML-Workflows.
- Google AI Platform: Google AI Platform ist eine Cloud-basierte Plattform, die Tools und Dienste für die Erstellung und den Einsatz von Modellen für maschinelles Lernen in der Google Cloud bereitstellt. Sie bietet verwaltete Dienste für das Training und die Bereitstellung von Modellen sowie die Integration mit TensorFlow und anderen gängigen ML-Frameworks.
Die Wahl der richtigen Software und Bibliotheken hängt von Faktoren wie der bevorzugten Programmiersprache, den Projektanforderungen und Skalierbarkeitsüberlegungen ab.
Schlussfolgerung für prädiktive Modelierung
Die prädiktive Modellierung ist ein leistungsstarkes Werkzeug, mit dem Unternehmen wertvolle Erkenntnisse aus Daten gewinnen und fundierte Entscheidungen über die Zukunft treffen können. Durch den Einsatz statistischer Algorithmen und maschineller Lernverfahren können Prognosemodelle Trends vorhersagen, Risiken erkennen und Prozesse in verschiedenen Branchen optimieren. Von der Vorhersage des Kundenverhaltens bis hin zur Aufdeckung betrügerischer Aktivitäten sind die Anwendungsmöglichkeiten von Prognosemodellen vielfältig und weitreichend. Wenn du die Grundlagen der Datenanalyse, Modellauswahl und -interpretation beherrschst, kannst du das Potenzial der prädiktiven Modellierung nutzen, um Innovationen voranzutreiben, die Effizienz zu verbessern und der Konkurrenz in der heutigen datengesteuerten Welt einen Schritt voraus zu sein.
Es ist jedoch von entscheidender Bedeutung, die Vorhersagemodellierung mit Vorsicht und Sorgfalt anzugehen, da selbst die ausgefeiltesten Modelle nicht vor Fehlern oder Verzerrungen gefeit sind. Eine kontinuierliche Überwachung, Validierung und Verfeinerung der Modelle ist unerlässlich, um ihre Genauigkeit und Relevanz im Laufe der Zeit sicherzustellen. Darüber hinaus ist die effektive Kommunikation von Modellergebnissen und -beschränkungen entscheidend für die Vertrauensbildung und die Erleichterung einer fundierten Entscheidungsfindung innerhalb von Organisationen. Durch einen systematischen und kollaborativen Ansatz bei der Vorhersagemodellierung können Unternehmen ihr volles Potenzial ausschöpfen und verwertbare Erkenntnisse gewinnen, die den Erfolg in der dynamischen und sich ständig weiterentwickelnden Landschaft des modernen Geschäftslebens fördern.
Wie kann man auf einfache Weise Daten für prädiktive Modellierung sammeln?
Erlebe die Leistungsfähigkeit der Echtzeit-Marktforschungsplattform von Appinio für prädiktive Modellierung. Mit Appinio kannst du innerhalb von Minuten deine eigene Marktforschung durchführen und wertvolle Erkenntnisse über deine Kunden gewinnen, die du in deine Prognosemodelle einfließen lassen kannst.