Appinio Research · 10.01.2025 · 39min read

Ever wondered how a simple concept like a Decision Tree can yield powerful insights and predictions in the complex world of machine learning? This guide is your compass in navigating the intricacies of Decision Trees.
From understanding their inner workings to mastering the art of tuning and optimizing, you'll gain a profound understanding of these versatile models. We'll demystify key concepts, explore various Decision Tree algorithms, and equip you with the tools to evaluate, interpret, and deploy them effectively.
What is a Decision Tree?
A Decision Tree is a supervised machine learning algorithm used for both classification and regression tasks. It is a tree-like structure where an internal node represents a feature, the branch represents a decision rule, and each leaf node represents an outcome.
Decision Trees are employed in data science to make decisions or predictions based on input features. They excel at handling both categorical and numerical data, making them versatile tools for various applications.
The primary purposes of Decision Trees are:
- Classification: Decision Trees classify data points into predefined categories or classes. For example, they can classify emails as spam or not spam, customers as potential buyers or non-buyers, and patients as having a specific disease or not.
- Regression: Decision Trees predict numerical values based on input features. They can estimate prices, scores, or quantities, making them useful for tasks like real estate price prediction, stock market forecasting, and more.
- Interpretability: Decision Trees offer an understandable representation of decision-making processes. They provide insights into which features are crucial for predictions, aiding in model interpretation and making them valuable in domains where transparency is essential, such as healthcare and finance.
Importance of Decision Trees in Data Science
Decision Trees hold significant importance in data science and machine learning for several reasons:
- Ease of Interpretation: Decision Trees are inherently interpretable. The graphical representation of the tree structure allows data scientists and stakeholders to understand the logic behind predictions easily. This interpretability is crucial in domains where decision-making processes need to be transparent.
- Versatility: Decision Trees can handle various data types, including categorical and numerical features, without requiring extensive preprocessing. This versatility simplifies the data preparation phase and accelerates model development.
- Feature Selection: Decision Trees provide feature importance scores, helping data scientists identify which features are most influential in making predictions. This feature selection capability aids in dimensionality reduction and improving model efficiency.
- Applicability: Decision Trees find applications in diverse domains, including healthcare (disease diagnosis), finance (credit scoring), marketing (customer segmentation), and natural language processing (sentiment analysis). Their adaptability to different tasks showcases their relevance across industries.
- Ensemble Methods: Decision Trees serve as the building blocks for powerful ensemble methods like Random Forests and Gradient Boosted Trees. These ensemble techniques combine multiple Decision Trees to enhance predictive accuracy and robustness.
Overview of Decision Tree Structure
A typical Decision Tree consists of the following components:
- Root Node: The topmost node representing the entire dataset and the initial decision point.
Internal Nodes: Nodes that represent features or attributes and serve as decision points for splitting the data. - Branches: Arrows connecting nodes and indicating the outcome of a decision rule based on feature values.
- Leaf Nodes: Terminal nodes representing the final prediction or classification result.
- Decision Rules: The criteria used at internal nodes to partition the data, such as "if feature A > X, go left; otherwise, go right."
The tree structure is constructed recursively through a process known as recursive partitioning, where the dataset is repeatedly split into subsets based on chosen features and criteria until a stopping condition is met.
Common Use Cases
Decision Trees find applications in a wide range of industries and problem domains. Some everyday use cases include:
- Customer Segmentation: Decision Trees help businesses segment their customer base for targeted marketing strategies, such as identifying high-value customers or understanding customer preferences.
- Credit Scoring: Financial institutions use Decision Trees to assess the creditworthiness of loan applicants, determining whether to approve or deny loan applications based on various factors.
- Healthcare Diagnosis: Medical professionals employ Decision Trees to diagnose disease, predict patient outcomes, and select appropriate treatments based on symptoms and medical data.
- Predictive Maintenance: Industries like manufacturing and utilities use Decision Trees to predict equipment failures and schedule maintenance, reducing downtime and operational costs.
- Recommendation Systems: E-commerce platforms and content providers use Decision Trees to recommend products, services, or content to users based on their preferences and behavior.
- Anomaly Detection: Decision Trees are valuable in detecting anomalies in various fields, such as fraud detection in financial transactions or network intrusion detection in cybersecurity.
Understanding the basics of Decision Trees lays a solid foundation for effectively leveraging this versatile machine learning algorithm in data science projects. Whether you're new to the field or a seasoned practitioner, Decision Trees offer valuable tools for making data-driven decisions and gaining actionable insights.
Key Concepts of Decision Trees
Before we delve deeper into the topic, let's explore some of the key concepts that form the foundation of Decision Trees. Understanding these concepts is essential for grasping how Decision Trees work and how to make the most of them in your machine learning projects.
Nodes and Edges
When discussing Decision Trees, we often refer to nodes and edges. Let's break down these fundamental components:
Nodes
Nodes are the fundamental building blocks of a Decision Tree. Each node represents a decision point or a test on a specific feature of the dataset. Here's a closer look at the different types of nodes:
- Root Node: This is the topmost node of the tree, representing the initial decision or test. It serves as the starting point for the decision-making process.
- Decision Nodes: These nodes come after the root node and represent intermediate decisions or tests. At each decision node, the algorithm evaluates a feature's value and decides which branch to follow.
- Leaf Nodes: The endpoints of the tree are known as leaf nodes. They provide the final decision or prediction. In a classification problem, each leaf node corresponds to a class label, while in regression, it represents a predicted value.
Edges
Edges in a Decision Tree are the connecting lines between nodes. Edges illustrate the flow of decisions from one node to another, helping you understand the decision-making process visually.
In practical terms, nodes and edges together form a tree-like structure that guides the algorithm through the data, ultimately leading to a decision or prediction.
Root Node, Decision Nodes, and Leaf Nodes
Understanding the roles and characteristics of different types of nodes in a Decision Tree is crucial for comprehending how decisions are made and predictions are generated.
Root Node
The root node is the starting point of the Decision Tree. It represents the first decision or test applied to the input data. All other nodes and branches stem from the root node.
Decision Nodes
Decision nodes, also known as intermediate nodes, appear between the root node and the leaf nodes. They are responsible for evaluating specific features or conditions in the data. The decision tree algorithm uses decision nodes to split the data into subsets based on the chosen criteria.
Leaf Nodes
At the end of each branch, you'll find leaf nodes. These nodes provide the final output or prediction of the Decision Tree. In classification tasks, each leaf node corresponds to a class label, while in regression, leaf nodes contain predicted values.
Understanding the sequence and flow from the root node through decision nodes to leaf nodes helps you comprehend how the Decision Tree reaches its final decisions or predictions.
Splitting Criteria
One of the critical aspects of building an effective Decision Tree is determining how to split the data at decision nodes. This process relies on splitting criteria, which define the conditions under which the data is divided into subsets.
Standard splitting criteria include:
- Gini Impurity: Measures the probability of misclassifying a randomly chosen element if it were labeled according to the distribution of classes in the subset.
- Entropy: Measures the level of disorder or impurity in a dataset. Lower entropy indicates a more homogenous subset.
- Mean Squared Error (MSE): Used in regression tasks, it calculates the variance of the target variable in a subset.
The choice of splitting criterion can significantly impact the structure and performance of your Decision Tree, and it's often a crucial decision in the modeling process.
Pruning
While Decision Trees can grow to be complex and overfit the training data, it's essential to prevent this by using a technique called pruning.
Pruning involves removing branches or nodes from the tree that do not contribute significantly to improving the model's performance on unseen data. This helps avoid overfitting, where the tree captures noise in the training data and performs poorly on new data.
Pruning can be done using various methods, such as cost-complexity pruning, which aims to find the right balance between model complexity and predictive accuracy.
Decision Tree Algorithms
Several algorithms are used to construct Decision Trees. Each algorithm has its own strengths, weaknesses, and suitability for different types of problems. Here's a brief overview of some popular Decision Tree algorithms:
- ID3 (Iterative Dichotomiser 3): This algorithm uses entropy as its splitting criterion and is primarily suited for classification tasks.
- C4.5: An extension of ID3, C4.5 can handle both classification and regression tasks and uses information gain or gain ratio as splitting criteria.
- CART (Classification and Regression Trees): CART is versatile and can handle both classification and regression. It uses Gini impurity for classification and MSE for regression.
- Random Forests: This ensemble method combines multiple Decision Trees to improve accuracy and reduce overfitting.
- Gradient Boosted Trees: A boosting algorithm that builds Decision Trees sequentially, each correcting its predecessor's errors.
The choice of which algorithm to use depends on your specific problem and dataset characteristics. Understanding the strengths and weaknesses of each algorithm is vital for making informed decisions in your machine learning projects.
In the upcoming sections, we'll explore how to build Decision Trees, evaluate their performance, and optimize their parameters to create robust and accurate models.
How to Make a Decision Tree?
Building a Decision Tree involves a series of crucial steps, from preparing your data to handling various data types and determining the optimal splitting criteria. Let's explore these steps in detail.
1. Data Preparation and Preprocessing
Adequate data preparation and preprocessing are essential prerequisites for building accurate Decision Trees. Here's how you should approach this crucial step:
- Data Cleaning: Remove any duplicate or irrelevant records from your dataset.
- Handling Outliers: Decide how to treat outliers, whether by removing them or transforming the data.
- Feature Scaling: Depending on the algorithm you're using, consider whether to scale your features, especially for methods sensitive to feature magnitude.
- Feature Engineering: Create new features or transform existing ones to enhance the model's performance.
- Data Splitting: Divide your dataset into training and testing sets to effectively evaluate the model's performance.
Data quality directly impacts the quality of the resulting Decision Tree, so investing time in this phase is critical. Enhancing your decision tree-building process with advanced data collection and analysis methods can lead to more robust and accurate results.
For a streamlined and efficient approach to data collection, check out Appinio. Appinio empowers you to gather real-time consumer insights, providing you with a wealth of data to inform your decision tree models.
Take the next step in optimizing your decision-making process by booking a demo with Appinio today and discover the benefits of data-driven insights!
2. Choosing the Right Splitting Criteria
Selecting the appropriate splitting criteria for your Decision Tree can significantly affect its performance. Here's an overview of the common criteria and their suitability:
- Gini Impurity: Ideal for classification problems, especially when you want to minimize misclassification.
- Entropy: Similar to Gini Impurity, entropy is a good choice for classification tasks, particularly when you want more balanced splits.
- Mean Squared Error (MSE): Primarily used for regression problems, MSE minimizes the variance within subsets.
- Information Gain: A criterion that measures the reduction in entropy or Gini impurity after a split. It's suitable for classification problems.
- Gain Ratio: An information-based criterion that accounts for the number of categories in a feature. It's beneficial when dealing with categorical features with varying numbers of classes.
The choice of splitting criteria should align with your specific problem and dataset characteristics, as it influences how the Decision Tree partitions the data.
3. Recursive Partitioning
Recursive partitioning is at the heart of building a Decision Tree. It's the process of repeatedly dividing the dataset into subsets based on the chosen splitting criteria. Here's how it works:
- Starting Point: The root node represents the entire dataset.
- Splitting: The algorithm selects the best feature and splitting point according to the chosen criterion, creating child nodes.
- Child Nodes: Each child node becomes a smaller subset of the data.
- Recursion: The process repeats recursively for each child node until a stopping criterion is met (e.g., a maximum depth is reached or a minimum number of samples per leaf node is achieved).
Recursive partitioning continues until all leaves are pure (in classification problems, all instances in a leaf node belong to the same class) or until stopping conditions are met.
4. Handling Missing Values
Dealing with missing values is a common challenge when working with real-world datasets. In Decision Trees, it's crucial to address missing values effectively to avoid biased splits and inaccurate predictions:
- Imputation: You can choose to impute missing values with a specific value (e.g., the mean or median for numerical features) or use techniques like forward-fill or backward-fill for time-series data.
- Special Treatment: For categorical features, you can create a separate category representing missing values.
- Splitting Strategy: Some algorithms allow for missing values to be treated as a separate branch in the tree, allowing the model to decide the best path for missing data.
The approach you take depends on the nature of the data and the specific Decision Tree algorithm you are using.
5. Handling Categorical Data
Decision Trees naturally handle categorical data, but you must know how to handle it effectively:
- One-Hot Encoding: Convert categorical variables into binary columns (0 or 1) for each category.
- Label Encoding: Assign numerical labels to categorical values. However, be cautious, as this can introduce unintended ordinal relationships.
- Ordinal Encoding: Use when categorical data has a natural order, like "low," "medium," and "high."
- Decision Tree Algorithms: Some algorithms, like ID3 and C4.5, can handle categorical data directly without encoding.
The choice of encoding method depends on the type of categorical data and the Decision Tree algorithm you are using. Selecting the right approach ensures that the algorithm effectively captures the information within your categorical features. With these essential steps in mind, you'll be well-equipped to build robust and accurate Decision Trees that can handle various data types and yield meaningful insights.
Decision Tree Algorithms
Decision Tree algorithms play a pivotal role in determining how well your model performs. Each algorithm has its own characteristics, strengths, and weaknesses. Let's explore some of the most popular Decision Tree algorithms in detail.
ID3 (Iterative Dichotomiser 3)
ID3 (Iterative Dichotomiser 3) was one of the earliest Decision Tree algorithms developed by Ross Quinlan. While it's less commonly used today, understanding its principles is valuable for grasping the evolution of Decision Tree algorithms.
Key Features of ID3:
- Entropy-Based Splitting: ID3 uses entropy as its splitting criterion. It aims to maximize the information gain in each split by minimizing the entropy or uncertainty in the resulting subsets.
- Categorical Data: ID3 works well with categorical data and is suited for classification tasks.
- No Pruning: ID3 doesn't incorporate pruning, which can lead to overfitting on the training data if the tree is allowed to grow too deep.
Despite its historical significance, ID3 has limitations, such as its inability to handle continuous data and its susceptibility to overfitting. Consequently, more modern algorithms have emerged.
C4.5
C4.5 is an extension of ID3, developed also by Ross Quinlan, to address some of its limitations and offer improved performance.
Key Features of C4.5:
- Entropy and Gain Ratio: C4.5 introduced the concept of using gain ratio as a splitting criterion, which addresses the bias of ID3 towards attributes with more categories.
- Handling Continuous Data: C4.5 can handle both categorical and continuous data effectively, making it versatile.
- Pruning: Unlike ID3, C4.5 incorporates pruning techniques to prevent overfitting, improving the generalization of the Decision Tree.
- Wide Applicability: C4.5 is suitable for classification and regression tasks.
C4.5's ability to handle both categorical and continuous data, along with its pruning capabilities, makes it a more robust choice compared to ID3.
CART (Classification and Regression Trees)
CART (Classification and Regression Trees) is a versatile Decision Tree algorithm introduced by Leo Breiman. It can handle both classification and regression tasks, making it widely used in practice.
Key Features of CART:
- Gini Impurity and Mean Squared Error: CART uses Gini impurity as the default splitting criterion for classification tasks. For regression, it employs mean squared error (MSE).
- Binary Trees: CART constructs binary trees, meaning each node has two child nodes, simplifying the tree structure.
- Pruning: Similar to C4.5, CART incorporates pruning techniques to reduce overfitting.
- Feature Importance: CART can calculate the importance of each feature, helping identify which features contribute most to the model's decisions.
CART's ability to handle both classification and regression tasks and its feature importance analysis make it a powerful choice for a wide range of machine learning problems.
Random Forests
Random Forests is an ensemble learning method that leverages Decision Trees to achieve higher accuracy and reduce overfitting.
Key Features of Random Forests:
- Bagging: Random Forests build multiple Decision Trees by bootstrapping the training data (sampling with replacement) and aggregating their predictions.
- Random Feature Selection: Each tree in a Random Forest only considers a random subset of features when making decisions. This reduces the risk of overfitting.
- High Accuracy: Random Forests are known for their high accuracy and robustness, making them suitable for various applications.
- Feature Importance: Random Forests can measure feature importance, providing insights into which features are most influential.
Random Forests excel in scenarios where Decision Trees alone might overfit or lack accuracy, making them a popular choice for complex tasks.
Gradient Boosted Trees
Gradient Boosted Trees (GBTs) is another ensemble method that combines the strengths of Decision Trees in a sequential manner.
Key Features of Gradient Boosted Trees:
- Boosting: GBTs build a sequence of Decision Trees, where each subsequent tree corrects the errors made by the previous ones.
- Gradient Descent: Gradient boosting employs gradient descent to minimize the residuals or errors in the model's predictions.
- Strong Predictive Power: GBTs often achieve high predictive accuracy and effectively capture complex relationships in data.
- Sensitivity to Hyperparameters: Tuning hyperparameters is crucial to prevent overfitting in GBTs.
GBTs are well-suited for a wide range of tasks, especially when aiming to maximize predictive accuracy and capture intricate patterns in the data.
Each Decision Tree algorithm has its unique characteristics and is suited to different scenarios. The choice of which algorithm to use depends on the nature of your data, the specific problem you're tackling, and your desired model performance. As you continue to explore Decision Trees, consider experimenting with these algorithms to find the best fit for your machine learning projects.
How to Evaluate Decision Trees?
Evaluating the performance of Decision Trees is crucial to ensure they provide accurate and reliable predictions. Let's explore the metrics and techniques used to assess both classification and regression trees, as well as strategies to avoid overfitting and underfitting.
Metrics for Classification Trees
When dealing with classification problems, several metrics help gauge the effectiveness of Decision Trees:
Accuracy
Accuracy measures the proportion of correctly classified instances out of the total number of instances in the dataset. It's one of the most straightforward metrics for classification.
Accuracy = (Number of Correct Predictions) / (Total Number of Predictions)
However, accuracy may not be the best metric when dealing with imbalanced datasets, where one class significantly outnumbers the others.
Precision and Recall
Precision measures the proportion of true positive predictions out of all positive predictions:
Precision = (True Positives) / (True Positives + False Positives)
Recall measures the proportion of true positive predictions out of all actual positives:
Recall = (True Positives) / (True Positives + False Negatives)
These metrics are particularly useful when the cost of false positives and false negatives differs significantly.
F1-Score
The F1-Score is the harmonic mean of precision and recall and provides a balance between the two:
F1-Score = 2 * (Precision * Recall) / (Precision + Recall)
It's a good choice when you want to consider both false positives and false negatives.
Metrics for Regression Trees
When dealing with regression tasks, you need different metrics to evaluate the performance of Decision Trees:
Mean Absolute Error (MAE)
Mean Absolute Error (MAE) measures the average absolute difference between the predicted values and the actual values:
MAE = Σ|Actual - Predicted| / n
Where:
- Σ denotes summation over all instances.
- n is the total number of instances.
- MAE is relatively robust to outliers compared to other metrics.
Mean Squared Error (MSE)
Mean Squared Error (MSE) calculates the average squared difference between predicted and actual values:
MSE = Σ(Actual - Predicted)^2 / n
MSE gives more weight to larger errors and is sensitive to outliers.
R-squared (R²)
R-squared (R²) measures the proportion of the variance in the dependent variable that is predictable from the independent variables. It ranges from 0 to 1, with higher values indicating a better fit:
R² = 1 - (Σ(Actual - Predicted)^2) / (Σ(Actual - Mean(actual))^2)
R-squared helps assess the goodness of fit of the regression model.
Cross-Validation
Cross-validation is a crucial technique to evaluate Decision Trees and ensure their generalization to unseen data. Popular cross-validation methods include k-fold cross-validation and leave-one-out cross-validation. These methods help assess how well the model performs on different subsets of the data and can highlight potential overfitting issues.
Overfitting and Underfitting
One of the critical challenges in working with Decision Trees is finding the right balance between overfitting and underfitting:
- Overfitting: Occurs when the tree is too complex, capturing noise in the training data, but performing poorly on new data. This can be mitigated by pruning the tree or limiting its depth.
- Underfitting: Occurs when the tree is too simple and fails to capture the underlying patterns in the data. This can be addressed by allowing the tree to grow deeper or using more complex algorithms.
Balancing these two extremes is essential for building a Decision Tree that generalizes well to unseen data. Cross-validation and hyperparameter tuning are valuable tools for managing overfitting and underfitting.
Decision Trees Tuning and Optimization
To harness the full potential of Decision Trees, you need to optimize them and fine-tune their parameters. Let's explore various strategies for optimization:
Hyperparameter Tuning
Hyperparameters are settings that you can adjust to optimize the performance of your Decision Tree. Common hyperparameters include:
- Maximum Depth: Limiting the depth of the tree to prevent overfitting.
- Minimum Samples per Leaf: Setting a minimum number of samples required to create a leaf node.
- Minimum Samples per Split: Specifying a minimum number of samples needed to split a node.
- Criterion: Choosing between Gini impurity and entropy for classification or MSE for regression.
Hyperparameter tuning involves experimenting with different combinations of hyperparameters to find the best configuration for your specific problem. Techniques like grid search or random search can be used to systematically explore the hyperparameter space.
Feature Selection
Not all features contribute equally to the decision-making process of a Decision Tree. Feature selection involves identifying and using only the most relevant features, which can lead to a more interpretable and efficient model. Techniques like feature importance scores can help you determine which features are most influential.
Handling Imbalanced Data
In real-world scenarios, datasets are often imbalanced, meaning one class significantly outnumbers the others. To handle imbalanced data, consider techniques such as:
- Resampling: Oversample the minority class or undersample the majority class to balance the dataset.
- Synthetic Data Generation: Use techniques like Synthetic Minority Over-sampling Technique (SMOTE) to create synthetic instances of the minority class.
- Cost-Sensitive Learning: Adjust the misclassification cost to give more weight to the minority class.
Dealing with Multiclass Classification
While Decision Trees are naturally suited for binary classification, they can be extended to handle multiclass classification. Common approaches include:
- One-vs-Rest (OvR): Train one binary classifier for each class, treating it as the positive class and the others as the negative class.
- Multinomial Classification: Some algorithms, like C4.5 and CART, can handle multiclass classification directly by splitting the data into multiple categories in each node.
Dealing with multiclass classification efficiently involves understanding the nuances of your specific problem and selecting the most appropriate strategy.
Optimizing Decision Trees through hyperparameter tuning, feature selection, handling imbalanced data, and managing multiclass classification challenges can significantly enhance their performance and applicability in real-world machine-learning projects.
How to Visualize Decision Trees?
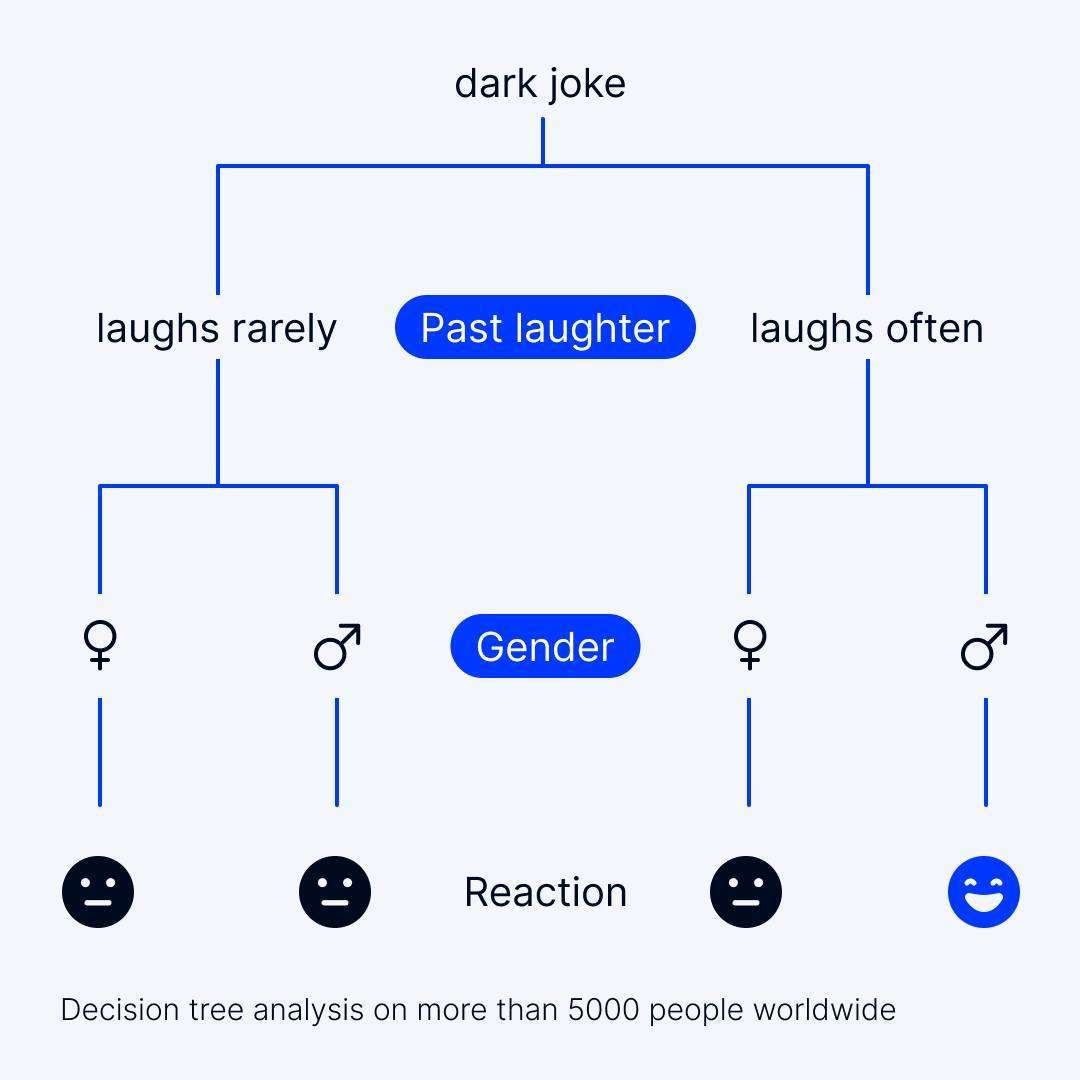
Interpreting Decision Trees and making their predictions understandable is crucial for both model development and stakeholder communication. Here, we explore various aspects of interpretability and visualization.
Visualizing Decision Trees
Visualizing Decision Trees helps you understand their structure and decision-making process. Visualization techniques include:
- Graphical Representations: You can create visual representations of Decision Trees, displaying nodes, edges, and decision criteria. Popular libraries like Graphviz or visualization tools provided by machine learning frameworks are helpful for this purpose.
- Tree Diagrams: Representing the Decision Tree as a tree diagram with nodes and branches helps make the model's decision logic explicit.
- Node Attributes: Enhance the visualizations with information such as feature names, splitting criteria, and class labels.
Visualizations not only aid in understanding how the model works but also in communicating its findings to non-technical stakeholders.
Feature Importance
Understanding the importance of different features in your Decision Tree model can guide feature selection and provide valuable insights. Techniques for assessing feature importance include:
- Gini Importance: For classification trees, the Gini importance measures how much each feature contributes to the overall Gini impurity reduction.
- Information Gain or Gain Ratio: These measures assess the information gain attributed to each feature when making splits in the tree.
- Mean Decrease in Accuracy (MDA): In ensemble methods like Random Forests, MDA measures the impact of each feature on model accuracy when the feature is removed.
By identifying the most influential features, you can focus on those during feature engineering and gain insights into the underlying data patterns.
Explainability and Model Interpretation
While Decision Trees are inherently interpretable, explaining their decisions to non-experts or stakeholders is still essential. Techniques for model interpretation include:
- Rule Extraction: Convert the Decision Tree into a set of human-readable rules that explain the conditions leading to specific predictions.
- Partial Dependence Plots: Visualize the relationship between a feature and the predicted outcome while keeping other features constant, helping to understand feature effects.
- SHAP (SHapley Additive exPlanations): A technique that provides a unified measure of feature importance and can be used to explain individual predictions intuitively.
Explainability is essential not only for gaining trust in the model but also for identifying potential biases and ethical considerations.
How to Analyze Decision Trees?
Decision Tree analysis is a critical phase in the machine learning workflow that involves examining and interpreting the results and insights gained from a Decision Tree model. This analysis goes beyond model training and evaluation, delving deeper into understanding how the tree makes decisions and extracting valuable information. Let's explore the main aspects of Decision Tree analysis.
Model Interpretation
Interpreting a Decision Tree is a fundamental step in analysis. It involves understanding how the tree uses features and criteria to make predictions or classifications. This includes:
- Feature Importance: Identify which features play a significant role in the decision-making process. Decision Trees can provide feature importance scores, helping you prioritize and focus on influential attributes.
- Node Evaluation: Examine individual nodes in the tree to understand the decision rules and criteria applied. For classification, this might involve analyzing Gini impurity or entropy values. For regression, assess the mean squared error (MSE) or other relevant metrics.
- Tree Structure: Visualize the tree structure to see the hierarchy of decisions and branches. Understanding the tree's layout can provide insights into which features have the most significant impact on the outcome.
Rule Extraction
Rule extraction is the process of translating the Decision Tree into a set of human-readable rules. These rules explain how the model makes decisions based on input features. Extracted rules are often presented in a format like "if-then" statements. For example:
If (Feature A > X) and (Feature B <= Y), then Class 1
If (Feature A <= X) and (Feature C > Z), then Class 2
Extracted rules offer a clear and concise way to explain the model's decision logic to stakeholders and domain experts, increasing transparency and trust in the model.
Visualizations
Visualizing the Decision Tree and its associated metrics can aid in analysis. Visualization techniques include:
- Tree Diagrams: Visual representations of the Decision Tree structure with nodes, branches, and leaf nodes. These diagrams provide a high-level overview of the decision hierarchy.
- Node Attributes: Visualization enhancements, such as color-coding nodes based on class distributions or adding labels with feature names and splitting criteria, make the tree more informative.
- Partial Dependence Plots: These plots show how a specific feature's values influence predictions while keeping other features constant. They help analysts understand feature effects.
Error Analysis
Analyzing errors made by the Decision Tree is crucial for model improvement. Examine instances where the model's predictions deviate from the true outcomes. Aspects of error analysis include:
- Misclassification Patterns: Identify common patterns or characteristics among instances that the model consistently misclassifies. This insight can guide feature engineering or model adjustments.
- Outliers: Investigate instances that are challenging for the model. Outliers may indicate data anomalies or the need for specialized handling.
- Overfitting: Check for signs of overfitting by assessing the tree's complexity and ability to generalize to unseen data. Pruning and hyperparameter tuning may be necessary to mitigate overfitting.
Business Impact Assessment
Consider the practical implications of the Decision Tree's predictions and classifications. Evaluate how the model's insights can be translated into actionable decisions, whether it's recommending marketing strategies, allocating resources, or making medical diagnoses. Assess the potential benefits and risks associated with deploying the model in a real-world context.
Decision Tree analysis is an iterative and exploratory process that helps data scientists, analysts, and stakeholders gain a deeper understanding of model behavior and decision-making. Through interpretation, rule extraction, visualization, error analysis, and business impact assessment, you can unlock valuable insights and ensure that your Decision Tree model aligns with the objectives and requirements of your specific application.
Decision Trees Best Practices
Developing and deploying Decision Tree models effectively involves adhering to best practices and considering various practical aspects. Let's delve into some key considerations.
Data Collection and Feature Engineering
The quality of your data and the features you use significantly impact the performance of your Decision Tree models. Here are some tips:
- Data Quality: Ensure your data is clean, free of outliers, and properly labeled.
- Feature Selection: Carefully select relevant features and avoid using redundant or irrelevant ones.
- Feature Engineering: Create new features that capture valuable information or transform existing ones to enhance model performance.
- Data Scaling: Normalize or standardize features, especially if you're using algorithms sensitive to feature magnitudes.
Proper data preparation and feature engineering can significantly improve your model's predictive power.
Model Deployment
Deploying a Decision Tree model into a real-world application involves several steps:
- Scalability: Ensure that your model can handle the expected load and data volume in production.
- Integration: Integrate the model seamlessly into your application or system, considering API endpoints and data flows.
- Monitoring: Implement monitoring systems to track model performance and detect anomalies or drift.
- Security: Protect sensitive data and model endpoints from potential threats.
Deploying a model responsibly and securely is as important as building an accurate one.
Monitoring and Maintenance
Models, including Decision Trees, require ongoing monitoring and maintenance:
- Regular Updates: Update your model as new data becomes available to maintain its accuracy.
- Monitoring Drift: Continuously monitor data drift to ensure your model remains relevant and performs well in changing conditions.
- Retraining: Establish retraining schedules to keep the model up to date with evolving patterns in the data.
Proactive monitoring and maintenance prevent models from becoming obsolete or making inaccurate predictions.
Ethical Considerations
Consider ethical implications when working with Decision Tree models:
- Bias Detection and Mitigation: Identify and mitigate biases in your data and model predictions to ensure fair outcomes.
- Transparency: Be transparent about how the model works and make efforts to explain its decisions.
- Privacy: Protect sensitive information when collecting and using data for model training.
- Compliance: Adhere to relevant data protection and privacy regulations, such as GDPR or HIPAA.
Ensuring ethical practices in model development is essential for building trust and avoiding legal and reputational risks.
By following these practical tips and best practices, you can maximize the effectiveness of your Decision Tree models while maintaining ethical standards and ensuring their reliability in real-world applications.
Decision Tree Template
A Decision Tree template serves as a structured framework or blueprint for creating Decision Trees in machine learning. It provides a standardized approach to designing and building Decision Trees, making the model development process more efficient and organized. Let's explore the key components and benefits of using a Decision Tree template.
Components of a Decision Tree Template
- Objective Definition: Clearly define the goal of your Decision Tree model. Are you building a classification or regression tree? What are the specific outcomes or predictions you aim to achieve?
- Data Collection and Preprocessing: Specify the data sources, data collection methods, and data preprocessing steps. This includes data cleaning, handling missing values, encoding categorical variables, and scaling numerical features.
- Feature Selection: Identify which features or attributes from the dataset will be used as input for the Decision Tree. Consider feature importance analysis to guide your selection.
- Splitting Criteria: Decide on the criteria the Decision Tree will use to split nodes. Typical criteria include Gini impurity, entropy, mean squared error (MSE), or gain ratio, depending on the type of task (classification or regression).
- Hyperparameter Tuning: Define the hyperparameters that need tuning, such as the maximum depth of the tree, minimum samples per leaf, or the choice of criterion. Specify the range or values to explore during the tuning process.
- Model Training: Outline the steps for training the Decision Tree on the training dataset. Specify any cross-validation techniques or strategies for handling imbalanced data.
- Evaluation Metrics: Determine the evaluation metrics that will be used to assess the model's performance. For classification, this may include accuracy, precision, recall, F1-score, or ROC-AUC. For regression, consider metrics like mean absolute error (MAE) or R-squared (R²).
- Interpretability and Visualization: Describe how the model's results will be visualized and interpreted. Decision Trees offer inherent interpretability, but you may also use techniques like rule extraction or partial dependence plots.
- Testing and Validation: Define the process for testing the trained model on a separate validation dataset or through cross-validation. Ensure the model generalizes well to unseen data.
- Deployment Plan: If applicable, outline the steps for deploying the Decision Tree model into a production environment. Consider scalability, integration, and monitoring.
Benefits of Using a Decision Tree Template
- Consistency: A template ensures that all Decision Trees within a project or organization follow a consistent structure and methodology. This consistency streamlines collaboration among team members and maintains a standardized approach to model development.
- Efficiency: Templates save time by providing a predefined structure and guidelines, reducing the need to start from scratch for each new project. This efficiency is particularly valuable when working on multiple machine learning tasks.
- Documentation: Decision Tree templates serve as documentation for your modeling process. They capture critical decisions, hyperparameters, and evaluation criteria, making understanding and reproducing results easier.
- Quality Control: Templates facilitate quality control by guiding model developers through best practices and standard procedures. This helps prevent common pitfalls and errors.
- Reusability: You can adapt and reuse Decision Tree templates for similar tasks or projects, making them valuable assets in your machine learning toolkit.
- Knowledge Transfer: Templates support knowledge transfer within teams or organizations. New team members can quickly grasp the modeling process and adhere to established standards.
- Compliance: In regulated industries, Decision Tree templates can help ensure compliance with industry-specific guidelines and regulations.
- Iterative Improvement: Templates can evolve over time as you gain experience and insights, allowing you to continuously refine and improve your Decision Tree modeling process.
By incorporating a Decision Tree template into your machine learning workflow, you can enhance the efficiency, consistency, and quality of your modeling efforts. Whether you're a beginner or an experienced data scientist, a well-structured template can be a valuable resource for successfully applying Decision Trees to various real-world problems.
Conclusion for Decision Trees
Decision Trees are robust and interpretable models that can be your go-to tool in machine learning. From classifying spam emails to predicting real estate prices, Decision Trees have a wide range of applications. Remember to choose the suitable algorithm, fine-tune your model, and keep ethical considerations in mind. With the knowledge and skills gained from this guide, you're well-prepared to embark on your machine learning journey with Decision Trees as your trusty companions.
But, the journey doesn't end here. The field of machine learning is vast and ever-evolving. So, keep exploring, experimenting, and pushing the boundaries of what you can achieve with Decision Trees and other machine learning techniques. With dedication and continuous learning, you'll unlock even more possibilities and make remarkable strides in the exciting world of data science and artificial intelligence.
How to Create a Decision Tree in Minutes?
Introducing Appinio, the real-time market research platform that puts the power of rapid data-driven decision-making in your hands. With Appinio, conducting your own market research has never been more exciting and accessible. Here's why you'll love using Appinio for collecting data for your decision trees:
- Lightning-Fast Insights: Get from questions to insights in minutes, ensuring you have the data you need precisely when you need it for your decision tree models.
- User-Friendly: No need for a Ph.D. in research. Our platform is so intuitive that anyone can use it, empowering you to gather valuable consumer insights effortlessly.
- Global Reach: Define your target group from a rich pool of over 1200 characteristics and survey participants in over 90 countries, giving you a global perspective for your Decision Trees.