Appinio Research · 14.01.2025 · 30min read

Have you ever wondered how businesses can understand what people really think about their products or services just by analyzing online reviews and social media comments? Sentiment analysis, also known as opinion mining, is the key to unlocking these insights. It's like having a superpower to decipher whether people are happy, frustrated, or indifferent from the words they write.
Sentiment analysis uses algorithms to analyze text data and determine the sentiment or opinion expressed within it. From understanding customer feedback to tracking brand perception and even predicting election outcomes, sentiment analysis plays a crucial role in today's data-driven world. In this guide, we'll explore everything you need to get started with sentiment analysis. Whether you're a business looking to improve customer satisfaction or a researcher diving into the world of natural language processing, we will equip you with the knowledge and tools to effectively harness the power of sentiment analysis.
What is Sentiment Analysis?
Sentiment analysis, also known as opinion mining, is the process of analyzing text to determine the sentiment or opinion expressed within it. Whether it's understanding customer feedback, tracking brand perception on social media, or analyzing public sentiment toward political candidates, sentiment analysis helps uncover valuable insights from textual data.
Importance of Sentiment Analysis
- Informed Decision Making: By analyzing sentiment, businesses can make data-driven decisions, identify trends, and adapt strategies accordingly.
- Customer Satisfaction: Understanding customer sentiment allows businesses to address concerns, improve products/services, and enhance overall customer satisfaction.
- Brand Monitoring: Sentiment analysis enables organizations to monitor brand perception, identify potential reputation risks, and engage with customers proactively.
- Market Intelligence: Analyzing sentiment in market research helps businesses understand consumer preferences, competitive landscapes, and emerging trends.
Sentiment Analysis Challenges and Limitations
- Ambiguity and Context: Sentiment analysis algorithms may struggle to understand nuances such as sarcasm, irony, and cultural context.
- Data Quality: Poorly structured or noisy data can impact the accuracy of sentiment analysis results.
- Subjectivity: Sentiment interpretation can be subjective and context-dependent, leading to variability in results.
- Language and Cultural Differences: Sentiment analysis models may perform differently across languages and cultures due to linguistic variations and cultural nuances.
Fundamentals of Sentiment Analysis
Sentiment analysis relies on several fundamental techniques and concepts to accurately analyze text data and extract meaningful insights about sentiment and emotions.
Text Preprocessing Techniques
Text preprocessing is a crucial step in sentiment analysis, as it involves cleaning and transforming raw text data into a format suitable for analysis. Here are some standard text preprocessing techniques:
- Tokenization: Tokenization involves breaking down text into individual words or tokens. This process is essential for further analysis as it allows the model to understand the structure of the text.
- Normalization: Normalization techniques ensure consistency in text data by converting all words to lowercase and removing punctuation marks. This prevents the model from treating the same word with different capitalizations as different entities.
- Stopword Removal: Stopwords are common words that do not carry significant meaning, such as "and", "the", and "is". Removing stopwords helps reduce noise in the data and improves the efficiency of sentiment analysis algorithms.
- Stemming and Lemmatization: Stemming and lemmatization are techniques used to reduce words to their root form. Stemming involves removing prefixes and suffixes from words to obtain their root, while lemmatization maps words to their base or dictionary form. This process helps reduce the dimensionality of the feature space and improve model performance.
Feature Extraction Methods
Feature extraction is the process of transforming raw text data into numerical features that can be used as input to machine learning models. Some common feature extraction methods used in sentiment analysis include:
- Bag-of-Words (BoW): The bag-of-words model represents text as a sparse matrix of word frequencies. Each document is represented as a vector where each element corresponds to the frequency of a particular word in the document. While simple and easy to implement, BoW does not consider the order of words in the text.
- Term Frequency-Inverse Document Frequency (TF-IDF): TF-IDF is a statistical measure used to evaluate the importance of a word in a document relative to a corpus. It assigns higher weights to words that are frequent in a document but rare in the overall corpus, making it helpful in identifying important keywords.
- Word Embeddings: Word embeddings are dense, low-dimensional representations of words learned from large text corpora using techniques like Word2Vec, GloVe, or FastText. Word embeddings capture semantic relationships between words, allowing models to generalize unseen data better and improve performance in sentiment analysis tasks.
Types of Sentiment Analysis
Sentiment analysis can be performed at different levels of granularity, depending on the scope of analysis and the specific objectives. Some common types of sentiment analysis include:
- Document-level Sentiment Analysis: In document-level sentiment analysis, the sentiment of an entire document, such as a review, article, or tweet, is analyzed as a whole. This approach provides an overall assessment of sentiment but may overlook nuances present at the sentence or phrase level.
- Sentence-level Sentiment Analysis: Sentence-level sentiment analysis focuses on analyzing the sentiment expressed within individual sentences. This approach allows for more fine-grained analysis and can capture variations in sentiment within a document.
- Aspect-based Sentiment Analysis: Aspect-based sentiment analysis aims to identify the sentiment associated with specific aspects or features of a product, service, or topic. This approach is instrumental in product reviews, where different aspects (e.g., performance, design, price) may elicit different sentiments.
Supervised vs. Unsupervised Learning Approaches
In sentiment analysis, machine learning algorithms can be categorized into supervised and unsupervised learning approaches based on the availability of labeled training data.
- Supervised Learning: In supervised learning, sentiment analysis models are trained on labeled datasets where each text sample is associated with a sentiment label (e.g., positive, negative, neutral). Supervised learning approaches require a significant amount of labeled data for training but often yield more accurate results, especially in well-defined sentiment classification tasks.
- Unsupervised Learning: Unsupervised learning approaches do not rely on labeled data for training. Instead, these models use techniques like clustering or dimensionality reduction to identify patterns and structures in the data without explicit supervision. Unsupervised learning can be useful in scenarios where labeled data is scarce or expensive to obtain, but it may require additional effort in interpreting the results and tuning parameters.
Understanding these fundamental concepts is essential for building effective sentiment analysis models and extracting meaningful insights from text data.
Data Collection for Sentiment Analysis
Before diving into sentiment analysis, you must ensure your data is well-prepared and structured for analysis.
Sourcing Data
Sourcing data is the first step in any data-driven analysis, including sentiment analysis. Depending on your specific application, you may collect data from various sources such as social media platforms, review websites, surveys, or feedback forms.
- Data Relevance: Ensure that the data you collect is relevant to your analysis objectives. For example, if you're analyzing sentiment towards a particular product, collect data from sources where users discuss or review that product.
- Data Volume: Aim to collect a sufficient volume of data to train robust sentiment analysis models. Larger datasets often result in more accurate and generalizable models.
- Data Quality: Pay attention to the quality of the data you collect. Noisy or unstructured data can adversely affect the performance of sentiment analysis models. Consider using data validation techniques to ensure data quality.
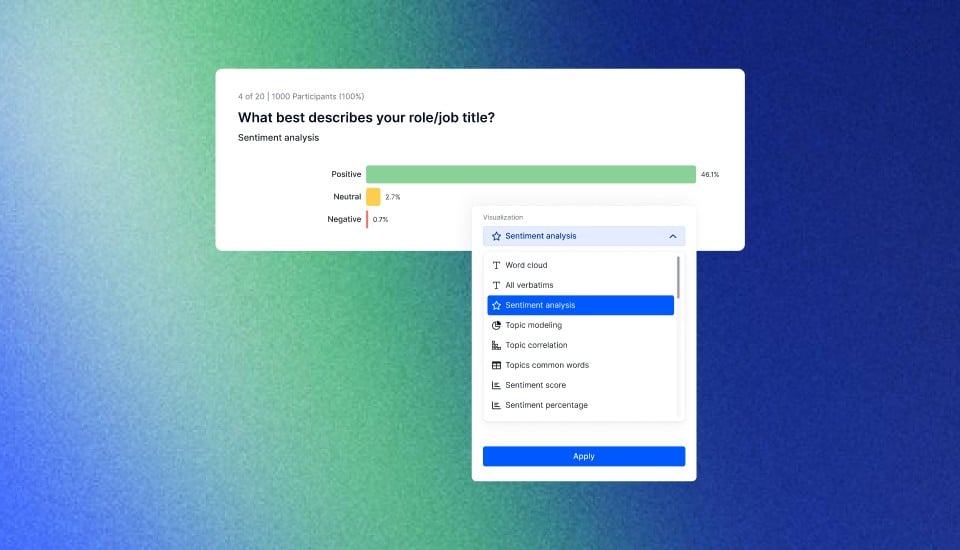
To unlock the full potential of sentiment analysis, it's crucial to lay a solid foundation with well-prepared data. By sourcing relevant, high-quality data and following best data collection and preparation practices, you set the stage for more accurate and insightful sentiment analysis outcomes. Appinio empowers you to seamlessly collect and analyze real-time consumer insights, providing the data-driven foundation you need to make informed decisions.
Ready to experience the power of Appinio? Book a demo today and discover how our platform can supercharge your sentiment analysis efforts!
Data Cleaning and Labeling
Once you've collected your data, the next step is to clean and label it for analysis. Data cleaning involves preprocessing the raw text data to remove noise and irrelevant information, while labeling involves assigning sentiment labels to the data samples. Here are some data cleaning and labeling techniques:
- Text Preprocessing: Apply text preprocessing techniques such as tokenization, normalization, stopword removal, and stemming/lemmatization to clean the text data and standardize its format.
- Noise Removal: Eliminate irrelevant information from the text data, such as HTML tags, special characters, or non-textual content like emojis or symbols.
- Labeling Guidelines: Define clear guidelines for labeling sentiment in your data. Decide on the sentiment categories (e.g., positive, negative, neutral) and establish criteria for assigning labels to data samples.
- Manual Labeling: In cases where sentiment labels cannot be inferred automatically, manually label the data by human annotators. Ensure inter-annotator agreement and consistency in labeling to maintain data quality.
Handling Imbalanced Data
Imbalanced datasets, where one sentiment class is significantly more prevalent than others, are common in sentiment analysis tasks. Imbalanced data can bias model predictions towards the majority class and lead to suboptimal performance. Here are some strategies for handling imbalanced data:
- Resampling Techniques: Balance the dataset by either oversampling the minority class or undersampling the majority class. Oversampling involves duplicating samples from the minority class, while undersampling involves randomly removing samples from the majority class.
- Synthetic Minority Over-sampling Technique (SMOTE): SMOTE is a popular oversampling technique that generates synthetic samples from the minority class using interpolation.
- Class Weighting: Adjust the class weights during model training to penalize misclassifications in the minority class more heavily. This helps the model prioritize learning from the minority class examples.
- Ensemble Methods: Ensemble methods like bagging and boosting can improve model performance on imbalanced data by combining predictions from multiple base models trained on different subsets of the data.
Splitting Data for Training and Testing
To evaluate the performance of sentiment analysis models, splitting the data into separate training and testing sets is essential. The training set is used to train the model, while the testing set is used to evaluate its performance on unseen data.
- Training-Testing Split Ratio: Determine the ratio of data to allocate to the training and testing sets. A common split is 80% for training and 20% for testing, but this can vary depending on the size of your dataset and the complexity of your model.
- Cross-Validation: Consider using cross-validation techniques such as k-fold cross-validation to assess model performance more robustly. Cross-validation involves partitioning the data into multiple subsets (folds) and training/testing the model on different combinations of these subsets.
By effectively sourcing, cleaning, labeling, and preparing your data, you'll set a solid foundation for building accurate and reliable sentiment analysis models.
Machine Learning Models for Sentiment Analysis
When it comes to sentiment analysis, a variety of machine learning models can be employed to analyze text data and extract sentiment. We'll explore some of the most popular models, techniques, and metrics commonly used in sentiment analysis tasks.
Traditional Models
Traditional machine learning models have been widely used in sentiment analysis tasks, offering simplicity and interpretability. Some common traditional models include:
- Naive Bayes: Naive Bayes is a probabilistic classifier based on Bayes' theorem, often used in text classification tasks including sentiment analysis. Despite its simplicity, Naive Bayes can achieve competitive performance, especially with large datasets.
- Support Vector Machines (SVM): SVM is a supervised learning algorithm that aims to find the optimal hyperplane to separate different classes. SVMs are particularly effective in high-dimensional spaces, making them suitable for sentiment analysis tasks with large feature spaces.
Deep Learning Models
Deep learning models have revolutionized sentiment analysis by leveraging the power of neural networks to learn complex patterns from data. Some popular deep learning models for sentiment analysis include:
- Recurrent Neural Networks (RNNs): RNNs are designed to process sequential data and are well-suited for analyzing text data. They can capture dependencies between words in a sequence, making them effective for tasks like sentiment analysis. However, RNNs suffer from the vanishing gradient problem and struggle to capture long-range dependencies.
- Convolutional Neural Networks (CNNs): CNNs excel at capturing local patterns in data through convolutional filters. In sentiment analysis, CNNs can learn to extract relevant features from text data, such as n-grams or word sequences, and classify sentiment based on these features.
Transfer Learning Techniques
Transfer learning techniques have gained popularity in sentiment analysis, allowing models to leverage pre-trained representations of language from large corpora. Some transfer learning techniques for sentiment analysis include:
- BERT (Bidirectional Encoder Representations from Transformers): BERT is a pre-trained language model that has been fine-tuned for various NLP tasks, including sentiment analysis. By fine-tuning BERT on task-specific data, you can leverage its contextual understanding of language to improve sentiment analysis performance.
- GPT (Generative Pre-trained Transformer): GPT is another pre-trained transformer-based model that can be fine-tuned for sentiment analysis tasks. GPT generates text by predicting the next word in a sequence, making it well-suited for generating text-based sentiment predictions.
Evaluation Metrics
To assess the performance of sentiment analysis models, various evaluation metrics can be used to measure their accuracy and effectiveness. These evaluation metrics include:
- Accuracy: Accuracy measures the proportion of correctly classified samples out of the total samples in the dataset. While accuracy provides a general indication of model performance, it may not be suitable for imbalanced datasets.
- Precision: Precision measures the proportion of true positive predictions among all positive predictions made by the model. It indicates the model's ability to avoid false positives.
- Recall: Recall measures the proportion of true positive predictions among all actual positive samples in the dataset. It indicates the model's ability to capture all positive instances in the dataset.
- F1 Score: The F1 score is the harmonic mean of precision and recall, providing a balanced measure of a model's performance. It considers both false positives and false negatives and is particularly useful for imbalanced datasets.
By understanding and selecting appropriate machine learning models and evaluation metrics, you can build robust sentiment analysis systems that accurately capture and analyze sentiment from text data.
Sentiment Analysis Uses and Applications
Here are some examples showcasing the versatility and effectiveness of sentiment analysis. They help provide concrete illustrations of how sentiment analysis is applied in various contexts, shedding light on its practical implications and potential benefits.
Customer Feedback Analysis

Imagine you're a business owner receiving numerous online reviews about your products or services. By applying sentiment analysis to these reviews, you can categorize them into positive, negative, or neutral sentiments.
 For instance, positive reviews might highlight aspects like excellent customer service or product quality, while negative reviews could point out areas for improvement, such as shipping delays or product defects. Analyzing the sentiment distribution over time allows you to track trends, identify recurring issues, and proactively address customer concerns, ultimately enhancing customer satisfaction and loyalty.
For instance, positive reviews might highlight aspects like excellent customer service or product quality, while negative reviews could point out areas for improvement, such as shipping delays or product defects. Analyzing the sentiment distribution over time allows you to track trends, identify recurring issues, and proactively address customer concerns, ultimately enhancing customer satisfaction and loyalty.
Social Media Monitoring
Social media platforms like Twitter, Facebook, and Instagram are rich sources of user-generated content, offering valuable insights into public sentiment and opinion. Sentiment analysis enables organizations to monitor real-time brand mentions, hashtags, and comments, gauging public sentiment toward their brand, products, or campaigns.
For example, during a product launch, sentiment analysis can help assess the initial reception, identify influencers or brand advocates, and respond promptly to any negative feedback or issues users raise. By actively engaging with the online community and addressing concerns, businesses can build trust, foster positive relationships, and cultivate a strong brand reputation.
Market Research and Competitive Analysis
In market research, sentiment analysis is a powerful tool for understanding consumer preferences, market trends, and competitive landscapes. For instance, analyzing sentiment in product reviews and online forums can reveal emerging trends, feature preferences, and competitor strengths and weaknesses.
By identifying market gaps and customer pain points, businesses can tailor their offerings to meet consumer needs more effectively, gain a competitive edge, and capitalize on new opportunities. Moreover, sentiment analysis can aid in benchmarking against competitors, providing valuable insights into how your brand stacks up in terms of customer sentiment and satisfaction.
Political Sentiment Analysis
During elections or political campaigns, sentiment analysis is pivotal in gauging public sentiment toward candidates, parties, and policy issues. Political analysts can track sentiment trends, identify key influencers, and assess voter sentiment in real time by analyzing social media conversations, news articles, and public forums. This information can inform campaign strategies, messaging tactics, and policy priorities, helping political candidates and parties connect with voters, address concerns, and shape public perception effectively.
These examples demonstrate the diverse applications and benefits of sentiment analysis across various domains, highlighting its potential to drive informed decision-making, enhance customer experiences, and foster positive outcomes. By leveraging sentiment analysis effectively, organizations can gain valuable insights, mitigate risks, and stay ahead in today's data-driven world.
Advanced Topics in Sentiment Analysis
As sentiment analysis continues to evolve, researchers and practitioners explore advanced topics and techniques to enhance the accuracy and effectiveness of sentiment analysis systems.
Domain Adaptation
Domain adaptation refers to the process of adapting sentiment analysis models to new domains or contexts where labeled data may be scarce or non-representative. In real-world applications, sentiment analysis models trained on one domain may not perform well when applied to another domain due to differences in vocabulary, style, or sentiment expressions.
Domain adaptation techniques aim to mitigate this domain shift by leveraging transfer learning or domain-specific features to adapt the model to the target domain. Examples of domain adaptation techniques include unsupervised domain adaptation, where the model learns domain-invariant features, and adversarial training, where the model is trained to discriminate between source and target domains.
Multimodal Sentiment Analysis
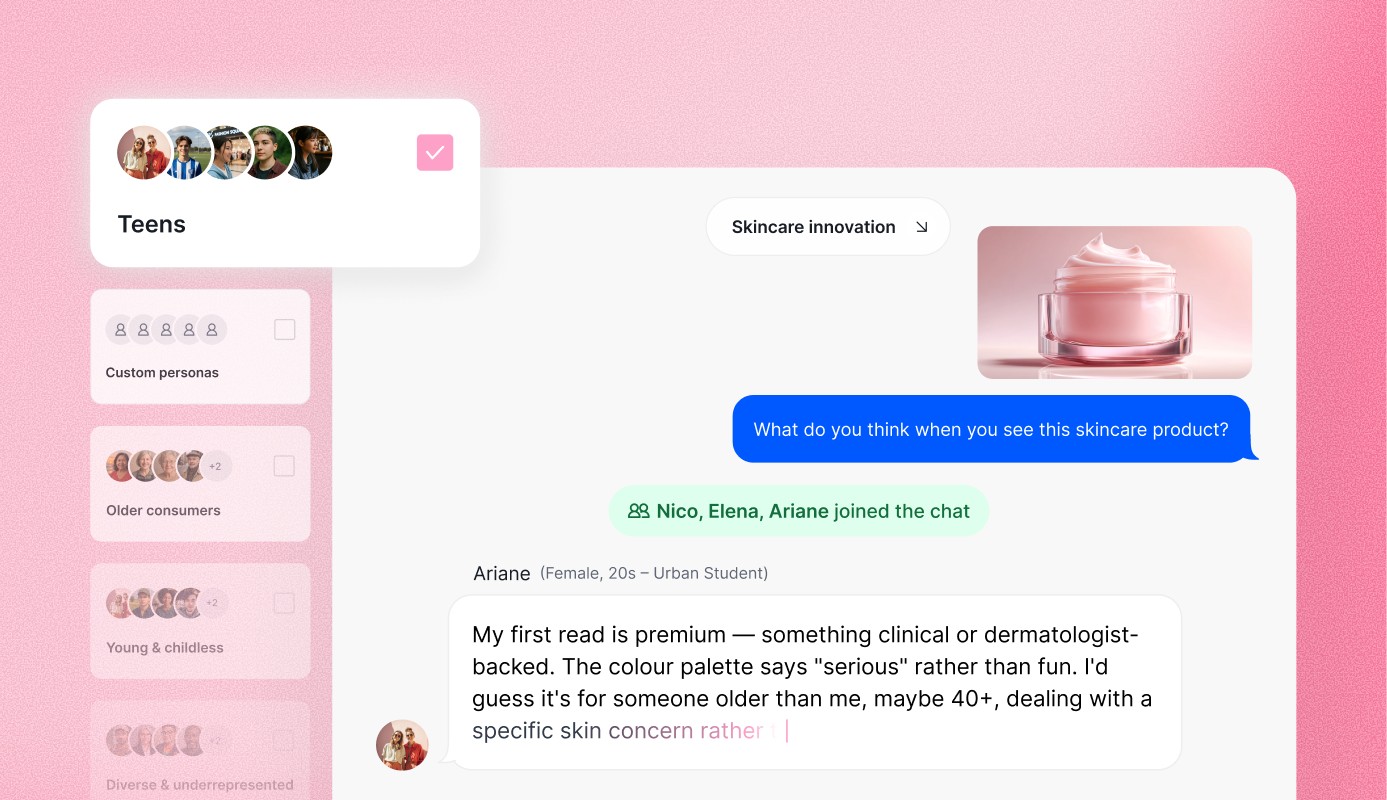
Multimodal sentiment analysis integrates information from multiple modalities, such as text, images, audio, and video, to enhance the understanding of sentiment. In many real-world scenarios, sentiment is expressed not only through text but also through visual and auditory cues.
For example, in product reviews, sentiment can be conveyed through the tone of voice in videos or the facial expressions in images. Multimodal sentiment analysis techniques leverage deep learning architectures capable of processing multiple modalities simultaneously, enabling more comprehensive sentiment analysis. By integrating information from diverse modalities, multimodal sentiment analysis can provide richer and more nuanced insights into sentiment expressions.
Sentiment Analysis in Social Media
Social media platforms have become rich sources of user-generated content, making them valuable for sentiment analysis. However, sentiment analysis in social media poses unique challenges due to the informal language, short text lengths, and the prevalence of sarcasm and irony. Social media sentiment analysis techniques often involve preprocessing steps tailored to handle noisy and informal text, such as hashtags, emojis, and slang.
Additionally, sentiment analysis models for social media may incorporate user-specific features, such as user profiles and social connections, to improve sentiment prediction accuracy. Sentiment analysis in social media enables organizations to monitor brand perception, track public sentiment toward specific topics or events, and identify emerging trends and influencers.
Handling Context and Sarcasm
Understanding context and sarcasm is essential for accurate sentiment analysis, as text often contains subtle nuances that influence sentiment interpretation. Contextual sentiment analysis techniques aim to capture the context surrounding text snippets to infer the intended sentiment accurately. This may involve analyzing preceding or succeeding text segments, identifying sentiment modifiers, or considering the broader context of the conversation.
Sarcasm detection in sentiment analysis presents a particularly challenging task, as sarcastic expressions often convey sentiments opposite to their literal meaning. Sarcasm detection techniques leverage linguistic cues, such as lexical ambiguity, incongruity, and sentiment reversals, to identify sarcastic utterances. By effectively handling context and sarcasm, sentiment analysis systems can provide more accurate and contextually relevant sentiment predictions, leading to better decision-making and insight extraction.
Sentiment Analysis Tools
When it comes to sentiment analysis, many tools and libraries are available to streamline the development process and empower analysts and developers to build robust sentiment analysis systems. Let's explore some of the key tools, libraries, and considerations for sentiment analysis.
Popular Sentiment Analysis Libraries
Several libraries and frameworks have gained popularity for their effectiveness and ease of use in sentiment analysis tasks:
- NLTK (Natural Language Toolkit): NLTK is a comprehensive library for natural language processing tasks, including sentiment analysis. It provides various tools and resources for text processing, such as tokenization, stemming, and part-of-speech tagging.
- SpaCy: SpaCy is a fast and efficient natural language processing library known for its performance and ease of use. It offers pre-trained models for tasks like part-of-speech tagging, named entity recognition, and dependency parsing, making it suitable for sentiment analysis tasks.
- TensorFlow: TensorFlow is an open-source machine learning framework developed by Google for building and training deep learning models. It offers high-level APIs like Keras for building neural networks, making it suitable for sentiment analysis tasks involving deep learning architectures.
- PyTorch: PyTorch is another popular deep learning framework known for its flexibility and dynamic computation graph. It provides a Pythonic interface for building and training neural networks, making it suitable for sentiment analysis tasks requiring flexibility and customization.
Sentiment Analysis APIs
For developers looking to integrate sentiment analysis into their applications quickly, sentiment analysis APIs offer a convenient solution. These APIs provide pre-trained sentiment analysis models accessible via simple HTTP requests, allowing developers to analyze text data with minimal setup. Some popular sentiment analysis APIs include:
- Google Cloud Natural Language API: offers sentiment analysis capabilities, along with other natural language processing features such as entity recognition and syntax analysis.
- Microsoft Azure Text Analytics API: provides sentiment analysis, key phrase extraction, and language detection capabilities, enabling developers to extract insights from text data effortlessly.
- IBM Watson Natural Language Understanding: offers sentiment analysis, emotion detection, and entity extraction capabilities, empowering developers to analyze text data comprehensively.
Custom Implementation Considerations
While pre-built libraries and APIs offer convenience, custom implementation of sentiment analysis models provides flexibility and control over the entire pipeline. Here are some key factors to consider:
- Data Availability: Ensure you have access to sufficient labeled data for training your custom sentiment analysis model. High-quality labeled data is crucial for building accurate and robust models.
- Model Selection: Choose the appropriate machine learning or deep learning model based on your data characteristics, task requirements, and computational resources. Experiment with different architectures and hyperparameters to find the optimal model for your sentiment analysis task.
- Feature Engineering: Explore various feature extraction techniques to represent text data effectively for sentiment analysis. Consider using word embeddings, TF-IDF vectors, or domain-specific features to capture meaningful information from text.
- Model Evaluation: Evaluate your custom sentiment analysis model using appropriate evaluation metrics, such as accuracy, precision, recall, and F1 score. Validate the model's performance on unseen data to ensure its generalization ability.
By leveraging these tools, libraries, and considerations, you can develop robust sentiment analysis systems tailored to your specific needs and requirements, whether through pre-built solutions or custom implementations.
Sentiment Analysis Best Practices
Effective sentiment analysis requires careful consideration of various factors, from data preprocessing to model selection and evaluation. Here are some best practices and tips to enhance the accuracy and reliability of your sentiment analysis systems:
- Define Clear Objectives: Clearly define the objectives and scope of your sentiment analysis project. Determine the specific sentiment categories of interest (e.g., positive, negative, neutral) and the target audience or domain.
- Preprocess Text Data: Invest time in preprocessing your text data to clean and standardize it. Apply techniques like tokenization, normalization, and stopword removal to prepare the data for analysis. Consider language-specific preprocessing steps based on the characteristics of your text.
- Collect Diverse Data: Ensure that your dataset includes diverse samples representing different demographics, geographic regions, and user segments, and leverage data collection tools like Appinio to simplify and automate the process. This helps to capture a comprehensive range of sentiments and avoids biases in the analysis.
- Leverage Domain Knowledge: Gain domain knowledge relevant to your sentiment analysis task. Understand the context in which sentiment is expressed, including industry-specific terminology, slang, and cultural nuances. Domain knowledge can help improve the accuracy and relevance of sentiment analysis results.
- Explore Feature Engineering: Experiment with different feature engineering techniques to represent text data effectively for sentiment analysis. Consider using word embeddings, TF-IDF vectors, or domain-specific features to capture meaningful information from text and improve model performance.
- Select Appropriate Models: Choose the appropriate machine learning or deep learning models based on your data characteristics, task requirements, and computational resources. Consider factors such as model complexity, interpretability, and scalability when selecting models for sentiment analysis.
- Evaluate Model Performance: Evaluate the performance of your sentiment analysis models using appropriate evaluation metrics, such as accuracy, precision, recall, and F1 score. Validate the models on diverse datasets and consider conducting cross-validation to assess robustness.
- Address Bias and Fairness: Be mindful of bias and fairness considerations in sentiment analysis. Evaluate models for bias across different demographic groups and take steps to mitigate bias in training data and model predictions. Consider incorporating fairness-aware techniques into your sentiment analysis pipeline.
- Monitor Model Performance: Continuously monitor the performance of your sentiment analysis models in real-world applications. Track changes in model performance over time and collect feedback from end-users to identify areas for improvement. Update models regularly to adapt to evolving language patterns and user preferences.
- Document and Share Insights: Document your sentiment analysis workflow, including data preprocessing steps, model selection criteria, and evaluation results. Share insights and findings with stakeholders to foster collaboration and informed decision-making. Consider creating visualizations or dashboards to communicate sentiment analysis results effectively.
Following these best practices and tips, you can develop robust and reliable sentiment analysis systems that provide valuable insights into the attitudes, emotions, and opinions expressed in text data.
Conclusion for Sentiment Analysis
Sentiment analysis offers a powerful tool for understanding and interpreting human emotions and opinions expressed in text data. By leveraging advanced algorithms and techniques, businesses, researchers, and individuals can gain valuable insights into customer preferences, brand perception, market trends, and more. From improving product offerings to enhancing customer satisfaction and informing strategic decision-making, sentiment analysis has the potential to drive positive outcomes across various domains. As technology continues to evolve, sentiment analysis will remain a vital component of the data analytics toolkit, empowering organizations to stay competitive, responsive, and attuned to the needs and sentiments of their stakeholders.
However, it's essential to acknowledge the challenges and limitations inherent in sentiment analysis, such as the ambiguity of language, cultural differences, and the subjective nature of sentiment interpretation. Despite these challenges, continuous advancements in machine learning, natural language processing, and data analytics hold promise for overcoming these obstacles and improving the accuracy and reliability of sentiment analysis systems.
How to Conduct Sentiment Analysis in Minutes?
Introducing Appinio, the real-time market research platform revolutionizing sentiment analysis. With Appinio, companies can effortlessly collect real-time consumer insights to fuel their data-driven decisions. Say goodbye to tedious research processes and hello to instant insights that drive business success.
Here's why Appinio is the ultimate tool for conducting sentiment analysis:
- Get from questions to insights in minutes: With our intuitive platform, you can design and deploy surveys in no time, allowing you to gather valuable sentiment data at lightning speed.
- No research degree required: Appinio's user-friendly interface makes it easy for anyone to conduct market research, regardless of their background. You don't need a PhD in research to navigate our platform and extract meaningful insights.
- Reach your target audience quickly and accurately: With access to over 1,200 characteristics and the ability to survey respondents in over 90 countries, you can precisely define your target group and gather sentiment data from the right audience.