What is Descriptive Statistics? Definition, Types, Examples
Appinio Research · 06.09.2024 · 37min read

Content
Have you ever wondered how we make sense of the vast sea of data surrounding us? In a world overflowing with information, the ability to distill complex datasets into meaningful insights is a skill of immense importance.
This guide will equip you with the knowledge and tools to unravel the stories hidden within data. Whether you're a data analyst, a researcher, a business professional, or simply curious about the art of data interpretation, this guide will demystify the fundamental concepts and techniques of descriptive statistics, empowering you to explore, understand, and communicate data like a seasoned expert.
What is Descriptive Statistics?
Descriptive statistics refers to a set of mathematical and graphical tools used to summarize and describe essential features of a dataset. These statistics provide a clear and concise representation of data, enabling researchers, analysts, and decision-makers to gain valuable insights, identify patterns, and understand the characteristics of the information at hand.
Purpose of Descriptive Statistics
The primary purpose of descriptive statistics is to simplify and condense complex data into manageable, interpretable summaries. Descriptive statistics serve several key objectives:
- Data Summarization: They provide a compact summary of the main characteristics of a dataset, allowing individuals to grasp the essential features quickly.
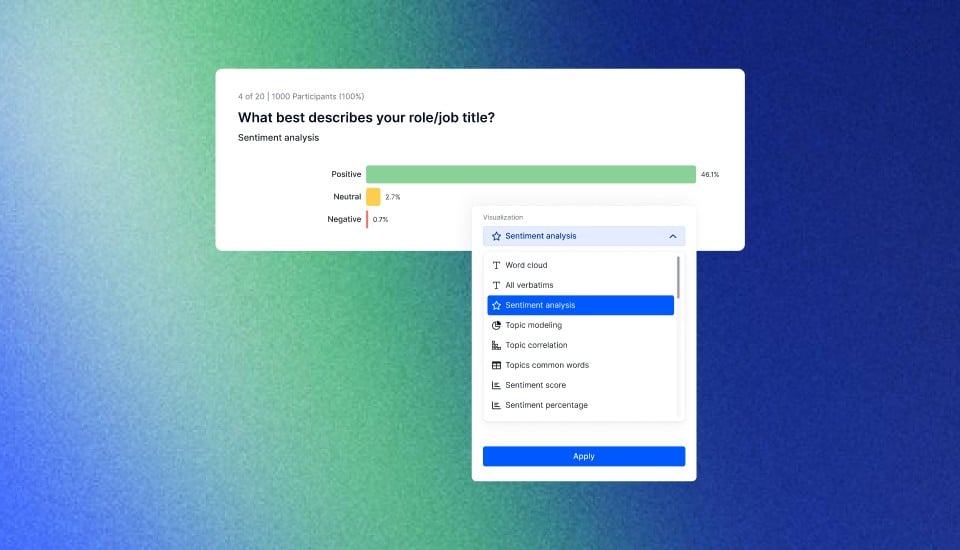
- Data Visualization: Descriptive statistics often accompany visual representations, such as histograms, box plots, and bar charts, making it easier to interpret and communicate data trends and distributions.
- Data Exploration: They facilitate the exploration of data to identify outliers, patterns, and potential areas of interest or concern.
- Data Comparison: Descriptive statistics enable the comparison of datasets, groups, or variables, aiding in decision-making and hypothesis testing.
- Informed Decision-Making: By providing a clear understanding of data, descriptive statistics support informed decision-making across various domains, including business, healthcare, social sciences, and more.
Importance of Descriptive Statistics in Data Analysis
Descriptive statistics play a pivotal role in data analysis by providing a foundation for understanding, summarizing, and interpreting data. Their importance is underscored by their widespread use in diverse fields and industries.
Here are key reasons why descriptive statistics are crucial in data analysis:
- Data Simplification: Descriptive statistics simplify complex datasets, making them more accessible to analysts and decision-makers. They condense extensive information into concise metrics and visual representations.
- Initial Data Assessment: Descriptive statistics are often the first step in data analysis. They help analysts gain a preliminary understanding of the data's characteristics and identify potential areas for further investigation.
- Data Visualization: Descriptive statistics are often paired with visualizations, enhancing data interpretation. Visual representations, such as histograms and scatter plots, provide intuitive insights into data patterns.
- Communication and Reporting: Descriptive statistics serve as a common language for conveying data insights to a broader audience. They are instrumental in research reports, presentations, and data-driven decision-making.
- Quality Control: In manufacturing and quality control processes, descriptive statistics help monitor and maintain product quality by identifying deviations from desired standards.
- Risk Assessment: In finance and insurance, descriptive statistics, such as standard deviation and variance, are used to assess and manage risk associated with investments and policies.
- Healthcare Decision-Making: Descriptive statistics inform healthcare professionals about patient demographics, treatment outcomes, and disease prevalence, aiding in clinical decision-making and healthcare policy formulation.
- Market Analysis: In marketing and consumer research, descriptive statistics reveal customer preferences, market trends, and product performance, guiding marketing strategies and product development.
- Scientific Research: In scientific research, descriptive statistics are fundamental for summarizing experimental results, comparing groups, and identifying meaningful patterns in data.
- Government and Policy: Government agencies use descriptive statistics to collect and analyze data on demographics, economics, and social trends to inform policy decisions and resource allocation.
Descriptive statistics serve as a critical foundation for effective data analysis and decision-making across a wide range of disciplines. They empower individuals and organizations to extract meaningful insights from data, enabling more informed and evidence-based choices.
Data Collection and Preparation
First, let's delve deeper into the crucial initial data collection and preparation steps. These initial stages lay the foundation for effective descriptive statistics.
Data Sources
When embarking on a data analysis journey, you must first identify your data sources. These sources can be categorized into two main types:
- Primary Data: This data is collected directly from original sources. It includes surveys, experiments, and observations tailored to your specific research objectives. Primary data offers high relevance and control over the data collection process.
- Secondary Data: Secondary data, on the other hand, is data that already exists and has been collected by someone else for a different purpose. It can include publicly available datasets, reports, and databases. Secondary data can save time and resources but may not always align perfectly with your research needs.
Data Types
Understanding the nature of your data is fundamental. Data can be classified into two primary types:
- Quantitative Data: Quantitative data consists of numeric values and is often used for measurements and calculations. Examples include age, income, temperature, and test scores. Quantitative data can further be categorized as discrete (countable) or continuous (measurable).
- Qualitative Data: Qualitative data, also known as categorical data, represents categories or labels and cannot be measured numerically. Examples include gender, color, and product categories. Qualitative data can be nominal (categories with no specific order) or ordinal (categories with a meaningful order).
Data Cleaning and Preprocessing
Once you have your data in hand, preparing it for analysis is essential. Data cleaning and preprocessing involve several critical steps:
Handling Missing Data
Missing data can significantly impact your analysis. There are various approaches to address missing values:
- Deletion: You can remove rows or columns with missing data, but this may lead to a loss of valuable information.
- Imputation: Imputing missing values involves estimating or filling in the missing data using methods such as mean imputation, median imputation, or advanced techniques like regression imputation.
Outlier Detection
Outliers are data points that deviate significantly from the rest of the data. Detecting and handling outliers is crucial to prevent them from skewing your results. Popular methods for identifying outliers include box plots and z-scores.
Data Transformation
Data transformation aims to normalize or standardize the data to make it more suitable for analysis. Common transformations include:
- Normalization: Scaling data to a standard range, often between 0 and 1.
- Standardization: Transforming data to have a mean of 0 and a standard deviation of 1.
Data Organization and Presentation
Organizing and presenting your data effectively is essential for meaningful analysis and communication. Here's how you can achieve this:
Data Tables
Data tables are a straightforward way to present your data, especially when dealing with smaller datasets. They allow you to list data in rows and columns, making it easy to review and perform basic calculations.
Graphs and Charts
Visualizations play a pivotal role in conveying the message hidden within your data. Some common types of graphs and charts include:
- Histograms: Histograms display the distribution of continuous data by dividing it into intervals or bins and showing the frequency of data points within each bin.
- Bar Charts: Bar charts are excellent for representing categorical or discrete data. They display categories on one axis and corresponding values on the other.
- Line Charts: Line charts are useful for identifying trends over time, making them suitable for time series data.
- Scatter Plots: Scatter plots help visualize the relationship between two variables, making them valuable for identifying correlations.
- Pie Charts: Pie charts are suitable for displaying the composition of a whole in terms of its parts, often as percentages.
Summary Statistics
Calculating summary statistics, such as the mean, median, and standard deviation, provides a quick snapshot of your data's central tendencies and variability.
When it comes to data collection and visualization, Appinio offers a seamless solution that simplifies the process. In Appinio, creating interactive visualizations is the easiest way to understand and present your data effectively. These visuals help you uncover insights and patterns within your data, making it a valuable tool for anyone seeking to make data-driven decisions.
Book a demo today to explore how Appinio can enhance your data collection and visualization efforts, ultimately empowering your decision-making process!
Measures of Central Tendency
Measures of central tendency are statistics that provide insight into the central or typical value of a dataset. They help you understand where the data tends to cluster, which is crucial for drawing meaningful conclusions.
Mean
The mean, also known as the average, is the most widely used measure of central tendency. It is calculated by summing all the values in a dataset and then dividing by the total number of values. The formula for the mean (μ) is:
μ = (Σx) / N
Where:
- μ represents the mean.
- Σx represents the sum of all individual data points.
- N is the total number of data points.
The mean is highly sensitive to outliers and extreme values in the dataset. It's an appropriate choice for normally distributed data.
Median
The median is another measure of central tendency that is less influenced by outliers compared to the mean. To find the median, you first arrange the data in ascending or descending order and then locate the middle value. If there's an even number of data points, the median is the average of the two middle values.
For example, in the dataset [3, 5, 7, 8, 10], the median is 7.
Mode
The mode is the value that appears most frequently in a dataset. Unlike the mean and median, which are influenced by the actual values, the mode represents the data point with the highest frequency of occurrence.
In the dataset [3, 5, 7, 8, 8], the mode is 8.
Choosing the Right Measure
Selecting the appropriate measure of central tendency depends on the nature of your data and your research objectives:
- Use the mean for normally distributed data without significant outliers.
- Choose the median when dealing with skewed data or data with outliers.
- The mode is most useful for categorical data or nominal data.
Understanding these measures and when to apply them is crucial for accurate data analysis and interpretation.
Measures of Variability
The measures of variability provide insights into how spread out or dispersed your data is. These measures complement the central tendency measures discussed earlier and are essential for a comprehensive understanding of your dataset.
Range
The range is the simplest measure of variability and is calculated as the difference between the maximum and minimum values in your dataset. It offers a quick assessment of the spread of your data.
Range = Maximum Value - Minimum Value
For example, consider a dataset of daily temperatures in Celsius for a month:
- Maximum temperature: 30°C
- Minimum temperature: 10°C
The range would be 30°C - 10°C = 20°C, indicating a 20-degree Celsius spread in temperature over the month.
Variance
Variance measures the average squared deviation of each data point from the mean. It quantifies the overall dispersion of data points. The formula for variance (σ²) is as follows:
σ² = Σ(x - μ)² / N
Where:
- σ² represents the variance.
- Σ represents the summation symbol.
- x represents each individual data point.
- μ is the mean of the dataset.
- N is the total number of data points.
Calculating the variance involves the following:
- Find the mean (μ) of the dataset.
- For each data point, subtract the mean (x - μ).
- Square the result for each data point [(x - μ)²].
- Sum up all the squared differences [(Σ(x - μ)²)].
- Divide by the total number of data points (N) to get the variance.
A higher variance indicates greater variability among data points, while a lower variance suggests data points are closer to the mean.
Standard Deviation
The standard deviation is a widely used measure of variability and is simply the square root of the variance. It provides a more interpretable value and is often preferred for reporting. The formula for standard deviation (σ) is:
σ = √σ²
Calculating the standard deviation follows the same process as variance but with an additional step of taking the square root of the variance. It represents the average deviation of data points from the mean in the same units as the data.
For example, if the variance is calculated as 16 (square units), the standard deviation would be 4 (the same units as the data). A smaller standard deviation indicates data points are closer to the mean, while a larger standard deviation indicates greater variability.
Interquartile Range (IQR)
The interquartile range (IQR) is a robust measure of variability that is less influenced by extreme values (outliers) than the range, variance, or standard deviation. It is based on the quartiles of the dataset. To calculate the IQR:
- Arrange the data in ascending order.
- Calculate the first quartile (Q1), which is the median of the lower half of the data.
- Calculate the third quartile (Q3), which is the median of the upper half of the data.
- Subtract Q1 from Q3 to find the IQR.
IQR = Q3 - Q1
The IQR represents the range within which the central 50% of your data falls. It provides valuable information about the middle spread of your dataset, making it a useful measure for skewed or non-normally distributed data.
Data Distribution
Understanding the distribution of your data is essential for making meaningful inferences and choosing appropriate statistical methods. In this section, we will explore different aspects of data distribution.
Normal Distribution
The normal distribution, also known as the Gaussian distribution or bell curve, is a fundamental concept in statistics. It is characterized by a symmetric, bell-shaped curve. In a normal distribution:
- The mean, median, and mode are all equal and located at the center of the distribution.
- Data points are evenly spread around the mean.
- The distribution is defined by two parameters: mean (μ) and standard deviation (σ).
The normal distribution is essential in various statistical tests and modeling techniques. Many natural phenomena, such as heights and IQ scores, closely follow a normal distribution. It serves as a reference point for understanding other distributions and statistical analyses.
Skewness and Kurtosis
Skewness and kurtosis are measures that provide insights into the shape of a data distribution:
Skewness
Skewness quantifies the asymmetry of a distribution. A distribution can be:
- Positively Skewed (Right-skewed): In a positively skewed distribution, the tail extends to the right, and the majority of data points are concentrated on the left side of the distribution. The mean is typically greater than the median.
- Negatively Skewed (Left-skewed): In a negatively skewed distribution, the tail extends to the left, and the majority of data points are concentrated on the right side of the distribution. The mean is typically less than the median.
Skewness is calculated using various formulas, including Pearson's first coefficient of skewness.
Kurtosis
Kurtosis measures the "tailedness" of a distribution, indicating whether the distribution has heavy or light tails compared to a normal distribution. Kurtosis can be:
- Leptokurtic: A distribution with positive kurtosis has heavier tails and a more peaked central region than a normal distribution.
- Mesokurtic: A distribution with kurtosis equal to that of a normal distribution.
- Platykurtic: A distribution with negative kurtosis has lighter tails and a flatter central region than a normal distribution.
Kurtosis is calculated using different formulas, including the fourth standardized moment.
Understanding skewness and kurtosis helps you assess the departure of your data from normality and choose appropriate statistical methods.
Other Types of Distributions
While the normal distribution is prevalent, real-world data often follows different distributions. Some other types of distributions you may encounter include:
- Exponential Distribution: Commonly used for modeling the time between events in a Poisson process, such as arrival times in a queue.
- Poisson Distribution: Used for counting the number of events in a fixed interval of time or space, such as the number of phone calls received in an hour.
- Binomial Distribution: Suitable for modeling the number of successes in a fixed number of independent Bernoulli trials.
- Lognormal Distribution: Often used for data that is the product of many small, independent, positive factors, such as stock prices.
- Uniform Distribution: Represents a constant probability over a specified range of values, making all outcomes equally likely.
Understanding the characteristics and properties of these distributions is crucial for selecting appropriate statistical techniques and making accurate interpretations in various fields of study and data analysis.
Visualizing Data
Visualizing data is a powerful way to gain insights and understand the patterns and characteristics of your dataset. Below are several standard methods of data visualization.
Histograms
Histograms are a widely used graphical representation of the distribution of continuous data. They are particularly useful for understanding the shape of the data's frequency distribution. Here's how they work:
- Data is divided into intervals, or "bins."
- The number of data points falling into each bin is represented by the height of bars on a graph.
- The bars are typically adjacent and do not have gaps between them.
Histograms help you visualize the central tendency, spread, and skewness of your data. They can reveal whether your data is normally distributed, skewed to the left or right, or exhibits multiple peaks.
Histograms are especially useful when you have a large dataset and want to quickly assess its distribution. They are commonly used in fields like finance to analyze stock returns, biology to study species distribution, and quality control to monitor manufacturing processes.
Box Plots
Box plots, also known as box-and-whisker plots, are excellent tools for visualizing the distribution of data, particularly for identifying outliers and comparing multiple datasets. Here's how they are constructed:
- The box represents the interquartile range (IQR), with the lower edge of the box at the first quartile (Q1) and the upper edge at the third quartile (Q3).
- A vertical line inside the box indicates the median (Q2).
- Whiskers extend from the edges of the box to the minimum and maximum values within a certain range.
- Outliers, which are data points significantly outside the whiskers, are often shown as individual points.
Box plots provide a concise summary of data distribution, including central tendency and variability. They are beneficial when comparing data distribution across different categories or groups.
Box plots are commonly used in fields like healthcare to compare patient outcomes by treatment, in education to assess student performance across schools, and in market research to analyze customer ratings for different products.
Scatter Plots
Scatter plots are a valuable tool for visualizing the relationship between two continuous variables. They are handy for identifying patterns, trends, and correlations in data. Here's how they work:
- Each data point is represented as a point on the graph, with one variable on the x-axis and the other on the y-axis.
- The resulting plot shows the dispersion and clustering of data points, allowing you to assess the strength and direction of the relationship.
Scatter plots help you determine whether there is a positive, negative, or no correlation between the variables. Additionally, they can reveal outliers and influential data points that may affect the relationship.
Scatter plots are commonly used in fields like economics to analyze the relationship between income and education, environmental science to study the correlation between temperature and plant growth, and marketing to understand the relationship between advertising spend and sales.
Frequency Distributions
Frequency distributions are a tabular way to organize and display categorical or discrete data. They show the count or frequency of each category within a dataset. Here's how to create a frequency distribution:
- Identify the distinct categories or values in your dataset.
- Count the number of occurrences of each category.
- Organize the results in a table, with categories in one column and their respective frequencies in another.
Frequency distributions help you understand the distribution of categorical data, identify dominant categories, and detect any rare or uncommon values. They are commonly used in fields like marketing to analyze customer demographics, in education to assess student grades, and in social sciences to study survey responses.
Descriptive Statistics for Categorical Data
Categorical data requires its own set of descriptive statistics to gain insights into the distribution and characteristics of these non-numeric variables. There are various methods for describing categorical data.
Frequency Tables
Frequency tables, also known as contingency tables, summarize categorical data by displaying the count or frequency of each category within one or more variables. Here's how they are created:
- List the categories or values of the categorical variable(s) in rows or columns.
- Count the occurrences of each category and record the frequencies.
Frequency tables are best used for summarizing and comparing categorical data across different groups or dimensions. They provide a straightforward way to understand data distribution and identify patterns or associations.
For example, in a survey about favorite ice cream flavors, a frequency table might show how many respondents prefer vanilla, chocolate, strawberry, and other flavors.
Bar Charts
Bar charts are a common graphical representation of categorical data. They are similar to histograms but are used for displaying categorical variables. Here's how they work:
- Categories are listed on one axis (usually the x-axis), while the corresponding frequencies or counts are shown on the other axis (usually the y-axis).
- Bars are drawn for each category, with the height of each bar representing the frequency or count of that category.
Bar charts make it easy to compare the frequencies of different categories visually. They are especially helpful for presenting categorical data in a visually appealing and understandable way.
Bar charts are commonly used in fields like market research to display survey results, in social sciences to illustrate demographic information, and in business to show product sales by category.
Pie Charts
Pie charts are circular graphs that represent the distribution of categorical data as "slices of a pie." Here's how they are constructed:
- Categories or values are represented as segments or slices of the pie, with each segment's size proportional to its frequency or count.
Pie charts are effective for showing the relative proportions of different categories within a dataset. They are instrumental when you want to emphasize the composition of a whole in terms of its parts.
Pie charts are commonly used in areas such as marketing to display market share, in finance to show budget allocations, and in demographics to illustrate the distribution of ethnic groups within a population.
These methods for visualizing and summarizing categorical data are essential for gaining insights into non-numeric variables and making informed decisions based on the distribution of categories within a dataset.
Descriptive Statistics Summary and Interpretation
Summarizing and interpreting descriptive statistics gives you the skills to extract meaningful insights from your data and apply them to real-world scenarios.
Summarizing Descriptive Statistics
Once you've collected and analyzed your data using descriptive statistics, the next step is to summarize the findings. This involves condensing the wealth of information into a few key points:
- Central Tendency: Summarize the central tendency of your data. If it's a numeric dataset, mention the mean, median, and mode as appropriate. For categorical data, highlight the most frequent categories.
- Variability: Describe the spread of the data using measures like range, variance, and standard deviation. Discuss whether the data is tightly clustered or widely dispersed.
- Distribution: Mention the shape of the data distribution. Is it normal, skewed, or bimodal? Use histograms or box plots to illustrate the distribution visually.
- Outliers: Identify any outliers and discuss their potential impact on the analysis. Consider whether outliers should be treated or investigated further.
- Key Observations: Highlight any notable observations or patterns that emerged during your analysis. Are there clear trends or interesting findings in the data?
Interpreting Descriptive Statistics
Interpreting descriptive statistics involves making sense of the numbers and metrics you've calculated. It's about understanding what the data is telling you about the underlying phenomenon. Here are some steps to guide your interpretation:
- Context Matters: Always consider the context of your data. What does a specific value or pattern mean in the real-world context of your study? For example, a mean salary value may vary significantly depending on the industry.
- Comparisons: If you have multiple datasets or groups, compare their descriptive statistics. Are there meaningful differences or similarities between them? Statistical tests may be needed for formal comparisons.
- Correlations: If you've used scatter plots to visualize relationships, interpret the direction and strength of correlations. Are variables positively or negatively correlated, or is there no clear relationship?
- Causation: Be cautious about inferring causation from descriptive statistics alone. Correlation does not imply causation, so consider additional research or experimentation to establish causal relationships.
- Consider Outliers: If you have outliers, assess their impact on the overall interpretation. Do they represent genuine data points or measurement errors?
Descriptive Statistics Examples
To better understand how descriptive statistics are applied in real-world scenarios, let's explore a range of practical examples across various fields and industries. These examples illustrate how descriptive statistics provide valuable insights and inform decision-making processes.
Financial Analysis
Example: Investment Portfolio Analysis
Description: An investment analyst is tasked with evaluating the performance of a portfolio of stocks over the past year. They collect daily returns for each stock and want to provide a comprehensive summary of the portfolio's performance.
Use of Descriptive Statistics:
- Central Tendency: Calculate the portfolio's average daily return (mean) to assess its overall performance during the year.
- Variability: Compute the portfolio's standard deviation to measure the risk or volatility associated with the investment.
- Distribution: Create a histogram to visualize the distribution of daily returns, helping the analyst understand the nature of the portfolio's gains and losses.
- Outliers: Identify any outliers in daily returns that may require further investigation.
The resulting descriptive statistics will guide the analyst in making recommendations to investors, such as adjusting the portfolio composition to manage risk or improve returns.
Marketing Research
Example: Product Sales Analysis
Description: A marketing team wants to evaluate the sales performance of different products in their product line. They have monthly sales data for the past two years.
Use of Descriptive Statistics:
- Central Tendency: Calculate the mean monthly sales for each product to determine their average performance.
- Variability: Compute the standard deviation of monthly sales to identify products with the most variable sales.
- Distribution: Create box plots to visualize the sales distribution for each product, helping to understand the range and variability.
- Comparisons: Compare sales trends over the two years for each product to identify growth or decline patterns.
Descriptive statistics allow the marketing team to make informed decisions about product marketing strategies, inventory management, and product development.
Social Sciences
Example: Survey Analysis on Happiness Levels
Description: A sociologist conducts a survey to assess the happiness levels of residents in different neighborhoods within a city. Respondents rate their happiness on a scale of 1 to 10.
Use of Descriptive Statistics:
- Central Tendency: Calculate the mean happiness score for each neighborhood to identify areas with higher or lower average happiness levels.
- Variability: Compute the standard deviation of happiness scores to understand the degree of variation within each neighborhood.
- Distribution: Create histograms to visualize the distribution of happiness scores, revealing whether happiness levels are normally distributed or skewed.
- Comparisons: Compare the happiness levels across neighborhoods to identify potential factors influencing happiness disparities.
Descriptive statistics help sociologists pinpoint areas that may require interventions to improve residents' overall well-being and identify potential research directions.
These examples demonstrate how descriptive statistics play a vital role in summarizing and interpreting data across diverse domains. By applying these statistical techniques, professionals can make data-driven decisions, identify trends and patterns, and gain valuable insights into various aspects of their work.
Common Descriptive Statistics Mistakes and Pitfalls
While descriptive statistics are valuable tools, they can be misused or misinterpreted if not handled carefully. Here are some common mistakes and pitfalls to avoid when working with descriptive statistics.
Misinterpretation of Descriptive Statistics
- Assuming Causation: One of the most common mistakes is inferring causation from correlation. Just because two variables are correlated does not mean that one causes the other. Always be cautious about drawing causal relationships from descriptive statistics alone.
- Ignoring Context: Failing to consider the context of the data can lead to misinterpretation. A descriptive statistic may seem significant, but it might not have practical relevance in the specific context of your study.
- Neglecting Outliers: Ignoring outliers or treating them as errors without investigation can lead to incomplete and inaccurate conclusions. Outliers may hold valuable information or reveal unusual phenomena.
- Overlooking Distribution Assumptions: When applying statistical tests or methods, it's important to check whether your data meets the assumptions of those techniques. For example, using methods designed for normally distributed data on skewed data can yield misleading results.
Data Reporting Errors
- Inadequate Data Documentation: Failing to provide clear documentation about data sources, collection methods, and preprocessing steps can make it challenging for others to replicate your analysis or verify your findings.
- Mislabeling Variables: Accurate labeling of variables and units is crucial. Mislabeling or using inconsistent units can lead to erroneous calculations and interpretations.
- Failure to Report Measures of Uncertainty: Descriptive statistics provide point estimates of central tendency and variability. It's crucial to report measures of uncertainty, such as confidence intervals or standard errors, to convey the range of possible values.
Avoiding Biases in Descriptive Statistics
- Sampling Bias: Ensure that your sample is representative of the population you intend to study. Sampling bias can occur when certain groups or characteristics are over- or underrepresented in the sample, leading to biased results.
- Selection Bias: Be cautious of selection bias, where specific data points are systematically included or excluded based on criteria that are unrelated to the research question. This can distort the analysis.
- Confirmation Bias: Avoid the tendency to seek, interpret, or remember information in a way that confirms preexisting beliefs or hypotheses. This bias can lead to selective attention and misinterpretation of data.
- Reporting Bias: Be transparent in reporting all relevant data, even if the results do not support your hypothesis or are inconclusive. Omitting such data can create a biased view of the overall picture.
Awareness of these common mistakes and pitfalls can help you conduct more robust and accurate analyses using descriptive statistics, leading to more reliable and meaningful conclusions in your research and decision-making processes.
Conclusion for Descriptive Statistics
Descriptive statistics are the essential building blocks of data analysis. They provide us with the means to summarize, visualize, and comprehend the often intricate world of data. By mastering these techniques, you have gained a valuable skill that can be applied across a multitude of fields and industries. From making informed business decisions to advancing scientific research, from understanding market trends to improving healthcare outcomes, descriptive statistics serve as our trusted guides in the realm of data.
You've learned how to calculate measures of central tendency, assess variability, explore data distributions, and employ powerful visualization tools. You've seen how descriptive statistics bring clarity to the chaos of data, revealing patterns and outliers, guiding your decisions, and enabling you to communicate insights effectively. As you continue to work with data, remember that descriptive statistics are your steadfast companions, ready to help you navigate the data landscape, extract valuable insights, and make informed choices based on evidence rather than guesswork.
How to implement Descriptive Statistics in Minutes?
Introducing Appinio, the real-time market research platform that's revolutionizing how businesses harness consumer insights. Imagine conducting your own market research in minutes, with the power of descriptive statistics at your fingertips.
Here's why Appinio is your go-to choice for fast, data-driven decisions:
-
Instant Insights: From questions to insights in minutes. Appinio accelerates your decision-making process, delivering real-time results when you need them most.
-
User-Friendly: No need for a PhD in research. Appinio's intuitive platform ensures that anyone can seamlessly gather and analyze data, making market research accessible to all.
-
Global Reach: Define your target group from 1200+ characteristics and survey it in over 90 countries. With Appinio, you can tap into a diverse pool of respondents worldwide.
Get facts and figures 🧠
Want to see more data insights? Our free reports are just the right thing for you!